Boost wget With Proxies: Setup, Use Cases, and Tips
A complete guide to configuring wget with HTTP, HTTPS, and SOCKS proxies. Boost privacy, bypass geo-blocks, and improve download stability.
How to
Fix pip Connection Issues with Proxies
Struggling with pip network errors or blocked access to PyPI? Learn how to set up proxies in pip, secure your connections, and keep installations running smoothly.
How to
Web scraping with R: Complete Guide for Beginners
Learn how to use R and rvest to scrape data from any website in this comprehensive tutorial: Inspect HTML elements, write CSS selectors, and store your scraped data in a tidy format.
Web scraping
Data Cleaning and Manipulation in Python: Best Practices & Techniques
Fix messy datasets with Python! Learn data cleaning techniques, including missing value handling, type conversion, and exporting clean data.
How to
How To Use Curl for Web Scraping
Let's explore the powerful capabilities of curl for web scraping. Our guide covers practical examples, automation with bash scripts, and best practices for efficient and ethical scraping.
How to
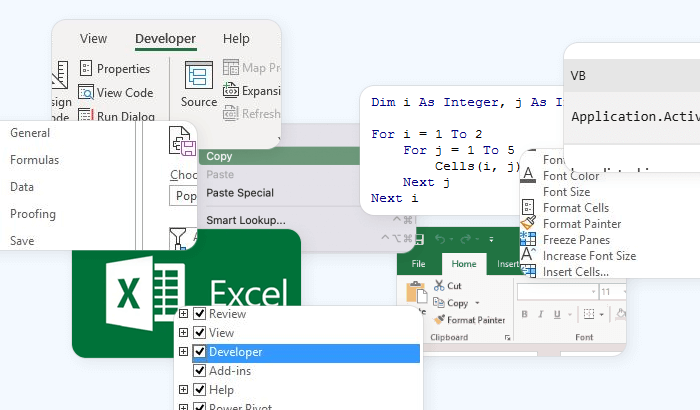
How to Scrape Web Data Using Excel VBA: A Complete Guide
Let's learn how to use Excel VBA for web scraping. Extract and store web data in Excel effortlessly with our detailed tutorial and troubleshooting advice.
Web scraping
Web scraping with PHP: Complete Guide for Beginners
Learn PHP web scraping with this comprehensive guide. Discover how to build a PHP scraper using cURL, handle HTTP requests, extract data, and optimize your scraping process.
Proxies and business
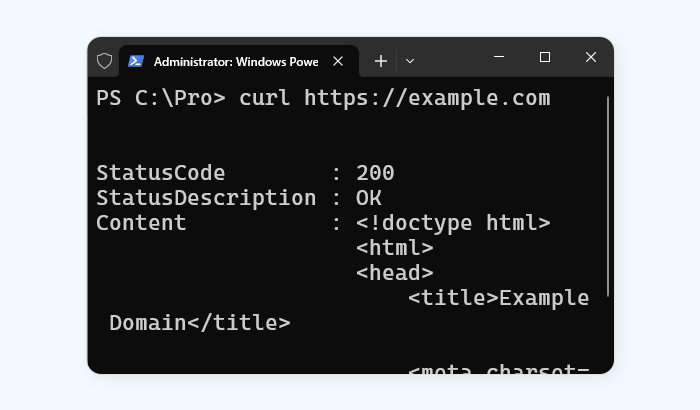
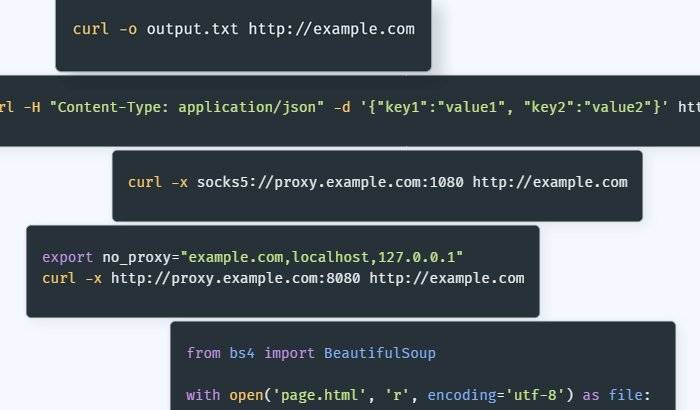
How to Use curl With Proxy
This guide shows how to use curl proxy to access geo-restricted websites. Learn different ways of setting up curl with a proxy and some examples of common commands.
Web scraping
Selenium Scraping With Node.js
Learn Selenium scraping with Node.js in this step-by-step guide. Discover how to set up, extract data, handle errors, and optimize performance with Infatica proxies for seamless scraping results.
How to
Web Scraping in Java
Discover how to perform web scraping in Java using libraries like Jsoup, Selenium, and HtmlUnit. Learn to extract and automate data collection from websites and export data efficiently.
How to
How to Scrape Job Postings: Tools, Techniques, and Real-World Insights
This in-depth guide covers everything you need to know about web scraping job postings, from tools to analysis. Let's uncover hiring trends and gain a competitive edge!
How to
Efficient and Easy Web Scraping with Scrapy
Let’s learn how to effectively use Scrapy for web scraping with this comprehensive guide – and explore techniques, handle challenges, and troubleshoot common issues to build efficient scrapers.
Get In Touch
Have a question about Infatica? Get in touch with our experts to learn how we can help.