






Article content


Jovana Gojkovic
11 min read
Amazon data is the company’s main asset: It’s a tech powerhouse that has managed to build a successful business model around web data. Nowadays, many companies are aiming to scrape Amazon to gain access to its data – and create better products using the insights it provides.
In this article, we’re taking a closer look at the entire Amazon data collection pipeline: We’ll explore the benefits it can offer, analyze its legal aspects (spoiler alert: it’s complicated), walk you through its setup process, analyze Infatica’s Amazon web scraping API, and more.
What is Amazon Data Scraping?
Web scraping in general means automated collection of data. The term automated is key here: Technically, saving each Amazon page manually does constitute data collection, but this process shares neither upsides nor downsides of a full-blown web scraping operation. Scraping Amazon can be performed with various tools and at different scales, but the end goal is the same: Use this data to generate value for your business or other people.
The Benefits of Scraping Amazon
Amazon product data offers a lot of valuable insight into customer behavior across many countries. With the right web scraping tools, you can collect and analyze it to better understand your own product.
Search engine optimization: Amazon’s platform is a search engine in and of itself. Not unlike Google, it has millions of users looking for the right product for the right price. Use Amazon data to improve your SEO performance as an Amazon seller or make your offering even more appealing to prospective customers.
Market trends analysis: Amazon’s product ecosystem is a living organism. Scrape Amazon to see the latest e-commerce trends, perform cost monitoring and price comparison, track top-selling products, and more.
Competitor monitoring: Amazon data can also highlight where your competition invests its resources.
Is scraping Amazon data legal?

We’ve recently written an extensive overview of web scraping legality – let’s recap its main points below. Please note, however, that this is not legal advice – it’s an analysis of latest legal practice related to this topic.We encourage you to contact law professionals to review each web scraping project on a case-by-case basis.
As of 2022, there’s still no law that either explicitly allows or prohibits scraping Amazon – what we have instead is a set of region-specific regulations and court decisions. These include:
- General Data Protection Regulation (GDPR) and
- Digital Single Market Directive (DSM) for Europe,
- California Consumer Privacy Act (CCPA) for California in particular,
- Computer Fraud and Abuse Act (CFAA) and
- The fair use doctrine for the US as a whole,
- And more.
Here’s the good news: Generally, regulators look favorably upon scraping data from Amazon, save for a few caveats. To keep the web scraping operation legal, you need to transform collected data in a meaningful way, generating new value for users – this is confirmed by the DSM directive and the fair use doctrine. A good example is scraping e-books for use in a natural language processing project. Conversely, you cannot simply copy all the information from the site and republish it – whatever the jurisdiction, this is a clear intellectual property law violation.

Some data owners disagree and take it to court, with a famous example of a legal battle that pitted LinkedIn against hiQ Labs, a small data analytics company that scraped the social network’s profiles. LinkedIn argued that this was illegal – and lost, with the court stating that:
It is likely that when a computer network generally permits public access to its data, a user’s accessing that publicly available data will not constitute access without authorization under the CFAA (Computer Fraud and Abuse Act.)
It can be argued that the same principle applies to Amazon’s data: You can collect it to create new products (e.g. a comparison shopping website), but simply copying and republishing it is more akin to intellectual property theft.
Why do you need a web scraping API?
An API (application programming interface) helps to unified interfaces that allow software to interact with each other. Different tech companies (e.g. Twitter, Facebook, YouTube, Steam, and many more) offer official APIs for developers to build new services atop these platforms.
In Amazon’s case, the API options are more limited. When it comes to Amazon product data, the company wants to stay a monopoly: Sharing this information freely with other e-commerce industry giants poses a significant risk to Amazon’s business model. The company’s existing APIs are great for product advertising and vendor operations – but if your goal is, say, price research, you need to use third-party solutions.
A web scraping API provides a foundation for organizing an Amazon data extraction pipeline. API developers do the heavy-lifting for you: write web scraping software that can sift through Amazon pages structure to detect relevant data; ensure that the API remains functional and doesn’t get blocked; provide extensive documentation and help with troubleshooting, and more – you just need to choose the data mining options (which Amazon product pages, which data format to use, etc.)
How to scrape Amazon Product Data
In this section, we’re providing a step-by-step guide to Infatica Scraper API – an easy-to-use yet powerful tool, which can be a great fit for both small- and large-scale projects. In this example, let’s see how to input various Amazon URLs to download their contents:
Step 1. Sign in to your Infatica account
Your Infatica account has different useful features (traffic dashboard, support area, how-to videos, etc.) It also has your unique user_key value which we’ll need to use the API – you can find it in your personal account’s billing area. The user_key value is a 20-symbol combination of numbers and lower- and uppercase letters, e.g. KPCLjaGFu3pax7PYwWd3.
Step 2. Send a JSON request
This request will contain all necessary data attributes. Here’s a sample request:
{
"user_key":"KPCLjaGFu3pax7PYwWd3",
"URLS":[
{
"URL":"https://www.amazon.com/Beelink-Quadruple-Powerful-Computer-Fingerprint/dp/B0B2X1BXG3/ref=lp_16225007011_1_1",
"Headers":{
"Connection":"keep-alive",
"User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0",
"Upgrade-Insecure-Requests":"1"
},
"userId":"ID-0"
}
]
}Here are attributes you need to specify in your request:
- user_key: Hash key for API interactions; available in the personal account’s billing area.
- URLS: Array containing all planned downloads.
- URL: Download link.
- Headers: List of headers that are sent within the request; additional headers (e.g. cookie, accept, and more) are also accepted. Required headers are: Connection, User-Agent, Upgrade-Insecure-Requests.
- userId: Unique identifier within a single request; returning responses contain the userId attribute.
Here’s a sample request containing 4 URLs:
{
"user_key":"7OfLv3QcY5ccBMAG689l",
"URLS":[
{
"URL":"https://www.amazon.com/Beelink-Quadruple-Powerful-Computer-Fingerprint/dp/B0B2X1BXG3/ref=lp_16225007011_1_1",
"Headers":{"Connection":"keep-alive","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0","Upgrade-Insecure-Requests":"1"},
"userId":"ID-0"
},
{
"URL":"https://www.amazon.com/Apple-MU8F2AM-A-Pencil-Generation/dp/B07K1WWBJK/ref=lp_16225007011_1_2",
"Headers":{"Connection":"keep-alive","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0","Upgrade-Insecure-Requests":"1"},
"userId":"ID-1"
},
{
"URL":"https://www.amazon.de/dp/B07F66M9RB",
"Headers":{"Connection":"keep-alive","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0","Upgrade-Insecure-Requests":"1"},
"userId":"ID-2"
},
{
"URL":"https://www.amazon.de/dp/B07VNFXXPQ/ref=sbl_dpx_B07ZYDGFSV_0?th=1",
"Headers":{"Connection":"keep-alive","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0","Upgrade-Insecure-Requests":"1"},
"userId":"ID-3"
}
]
}Step 3. Get the response and download the files
When finished, the API will send a JSON response containing – in our case – four download URLs. Upon receiving the response, notice its attributes: Status (HTTP status) and Link (file download link.) Follow the links to download the corresponding contents.
{
"ID-0":{"status":996,"link":""},
"ID-1":{"status":200,"link":"https://www.domain.com/files/product2.txt"},
"ID-2":{"status":200,"link":"https://www.domain.com/files/product3.txt"},
"ID-3":{"status":null,"link":""}
}Please note that the server stores each file for 20 minutes. The optimal URL count is below 1,000 URLs per one request. Processing 1,000 URLs may take 1-5 minutes.
How to Scrape Other Amazon Pages

You may also be interested in data from other types of Amazon pages, which provide additional insight into how products perform. Let’s see how to scrape these pages:
Search Page
The Search page’s structure is simple – here’s an example:
https://www.amazon.com/s?k=KEYWORD. The keyword may contain spaces, which need to be safely encoded to avoid errors during processing:
https://www.amazon.com/s?<wireless+mouse>.
Furthermore, you can modify the search URL via extra parameters like price, seller, marketplace, and more.
Sellers Page
Unlike the Search page, Sellers features a different page structure. To access it, send an AJAX request with the ASIN (Amazon Standard Identification Number):
https://www.amazon.com/gp/aod/ajax/ref=dp_aod_NEW_mbc?asin=B01MUAGZ48. In this example, the ASIN is B01MUAGZ48.
Infatica Scraper API: Web Scraping Made Easier
When shopping for Amazon Scraping APIs, a few solutions may catch your eye. Each API has its distinct features and limitations – but we feel that Infatica’s suite has the most to offer. Let’s take a closer look at its main features:
Dynamic content support
Most modern platforms use dynamic content to allow interaction between the users and the website. This is made possible thanks to JavaScript – but many web scrapers are unable to parse JavaScript code and effectively ignore large portions of websites.
Infatica’s Scraper API features a robust JavaScript rendering engine, making JavaScript execution possible – just like in a home browser. With dynamic content support, scraping Amazon data (e.g. real-time price updates or different page layouts) becomes possible, with Scraper API ensuring that all the data gets collected.
CSV, XLSX, and JSON support
You’ve managed to scrape Amazon without a hiccup – now you need a way of storing and organizing this data for easy use. The most popular file formats for doing this are CSV and XLSX (optimal for tabular data) and JSON (optimal for web applications.) You may have thousands of entries and rows of product data – and to help you analyze it at scale, Infatica’s Scraper API can save it as an XLSX, JSON, or CSV file.
More automation
To unlock the potential of scraping Amazon product data, you need to do this at scale – saving each web page manually won’t deliver the results we need. This is why companies utilize specialized scraping tools to allow for more scalability. Infatica Scraper features a powerful REST API that makes extracting information much easier.
Bonus: 3 Web Scraping Tips
Every data collection pipeline is complicated, with each component that can make or break the entire project. Here are a few tips that can help you scrape Amazon data much simpler and quicker.
Use the Right Amazon Proxy
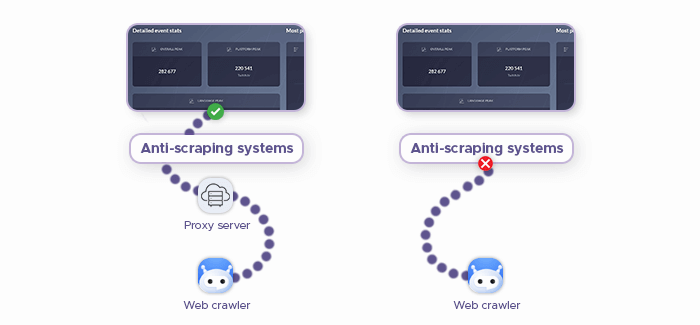
Amazon’s main asset is its data, which they try to safeguard – and all large websites invest into some form of basic anti-scraping measures. One of these measures is anti-scraping systems like reCAPTCHA and Cloudflare, which try to segregate human visitors and bots. Upon detecting a bot that tries to scrape Amazon data, they may block its requests and even its IP address.
Thankfully, proxies solve this problem: A proxy is a network utility that acts as a middleman between the user (or the scraper/crawler) and the target server. It masks the IP address, making it harder for anti-scraping systems to tell that the given user, in fact, is using automation to collect data from Amazon.
Residential proxies are particularly valuable. As their name suggests, they provide residential IP addresses, which are sourced from local internet service providers via regular users’ desktop computers and mobile devices. Equipped with a residential proxy, your web scraper’s requests will be practically indistinguishable from those of a human user.
Choosing and managing a proxy is a whole new set of challenges – and Infatica can help you with this problem, too. We have a large proxy pool that can be seamlessly integrated with Infatica Scraper API, making your web scraping workflow much simpler: We manage the technical side of the proxy network and guarantee its reliability.
Use Correct Geo-targeting
With Amazon offering local versions for various countries, using geo-targeting is important: The scraper’s requests should feature the correct geo-targeting options – otherwise, Amazon may return data from the wrong web page. To avoid this problem, perform geo-targeting via local proxies: For instance, if you want to see the German version of a particular search result page, use German proxies.
Choose the right scraping approach
Depending on your project’s scale, you have a number of approaches to choose from: One option involves crawling categories of each keyword to access product pages in each category. For larger-scale operations, you can try setting up a database with a list of unique product identifiers – and have your web scraper fetch these pages, say, on a monthly basis.
Conclusion
Although it’s sometimes tricky to scrape Amazon without a single roadblock, we hope this overview will help you avoid the most common problems. Have fun building new products!
Frequently Asked Questions
Scraper API is a powerful scraping software that allows you to crawl the Amazon website at a large
scale, in real time. As a tool for professional data collection, Scraper API makes extracting product
data easier via automating different tasks like bulk scrape jobs, scheduled scrape processes, customized
extraction rules, and more.
You can collect every product- and seller-related information from various product pages, including:
product lists in various categories, product specifications, customer reviews, price data, shipping
info, sales ranking, product descriptions, "Customers who bought this item also bought…" data,
and more.
Most users want to scrape this platform to unlock large quantities of actionable data
related to Amazon products, meaning data that can help you make informed decisions. This way, you can
analyze and predict trends and build better products like price aggregators, ecommerce platforms (not
unlike Amazon itself), SEO services, cybersecurity software, and more.
Accessing data from Amazon can become tricky when its scraping systems start blocking your requests. The
optimal way of solving this problem is using proxies, which mask the IP address. Using
proxies, web scrapers will have a much easier time flying under reCAPTCHA’s or Cloudflare’s radars.
A well-functioning data collection pipeline usually involves web scraping software and a set of proxies.
You can use free versions of these tools to scrape Amazon data, but your user experience may
not be ideal: Generally, free scrapers come with a set of restrictions (e.g. request count limit), while
free proxies are more likely to be detected and blocked when trying to access data from Amazon.
All in all, free options are OK in a new project when you’re just testing how a particular platform
(e.g. Amazon) handles scraping data.
If we ignore third-party associated costs (e.g. subscribing to a proxy service), scraping Amazon product
data itself is free: Some websites offer official APIs which provide paid access to their data (e.g.
$X for Y new files and Z new URLs), but Amazon doesn’t do that.
A headless browser is a modification of a regular web browser that lacks the “head”, i.e. its graphical
user interface. This makes it more light-weight and suitable for automation, which developers realize
via making it follow commands.
Although headless browsers are powerful, they can be omitted in many scenarios and HTTP requests can be
used instead to extract data reliably.
There’s a wide range of acceptable user agents that can help you scrape Amazon data. The most popular
ones are:
Chrome 101.0 + Windows 10 (9.9% of users), Firefox 100.0 + Windows
10 (8.1% of users), and Chrome 101.0 + macOS (5.1% of users.)
More importantly, you should set up your scraping tool for regular user agent rotation to avoid
detection.




{kind=link}
{kind=link}