






Article content


Denis Kryukov
13 min read
Reddit is the world’s most popular forum: With 430+ million monthly active users, the Reddit community is constantly generating unique content and discussions about virtually any topic imaginable. Reddit web data, therefore, can be valuable for your business – but how can you access it?
In this article, we’re taking a closer look at setting up a Reddit web scraping pipeline: We’ll show you how to use Infatica’s Scraper API – or build a Reddit scraper yourself with Python to collect Reddit posts, subreddit info, and comments.
What is Reddit Web scraping?
Web scraping in general means “automatic collection of publicly available data from a website or online service.” Notice the word “automatic”: If we open a random Reddit URL and click the Save page… button in our browsers, this wouldn’t be seen as web scraping – the scale of such data collection is just too small.
Reddit scraping can be performed using various tools, which typically differ in ease: Scrapers with visual interfaces (e.g. browser extensions or standalone desktop apps) are user-friendly and require no programming knowledge; APIs and home-built bots are harder to utilize right, but offer much richer functionality: for example, Reddit’s Python wrapper for bots allows to parse comment-heavy posts with ease.
Why Scrape Reddit?
Most Reddit profiles are real users that generate valuable insight into customer behavior via interacting with the platform: Submitting and upvoting posts, writing comments, and more. With millions of posts and billions of comments, you can:
Create aggregation services that feature the most interesting content – posts, images, videos, etc. – to provide limitless entertainment to your prospective users.
Perform trends and public opinion monitoring, which is easy thanks to Reddit’s large user base.
Keep in touch with your customers via company- and industry-focused subreddits that attract interested users, and more.
How to Scrape Reddit Posts with Infatica API
One way of collecting data involves Infatica’s Scraper API – an industry-leading web scraping tool, which can be a great fit for both small- and large-scale projects. In this example, let’s see how to input various URLs to download their contents:
Step 1. Sign in to your Infatica account
Your Infatica account has different useful features (traffic dashboard, support area, how-to videos, etc.) It also has your unique user_key value which we’ll need to use the API – you can find it in your personal account’s billing area. The user_key value is a 20-symbol combination of numbers and lower- and uppercase letters, e.g. KPCLjaGFu3pax7PYwWd3.
Step 2. Send a JSON request
This request will contain all necessary data attributes. Here’s a sample request:
{
"user_key":"KPCLjaGFu3pax7PYwWd3",
"URLS":[
{
"URL":"https://www.reddit.com/r/fatFIRE/comments/vnqfx7/how_do_you_use_money_to_automate_the_busywork_of/",
"Headers":{
"Connection":"keep-alive",
"User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0",
"Upgrade-Insecure-Requests":"1"
},
"userId":"ID-0"
}
]
}Here are attributes you need to specify in your request:
- user_key: Hash key for API interactions; available in the personal account’s billing area.
- URLS: Array containing all planned downloads.
- URL: Download link.
- Headers: List of headers that are sent within the request; additional headers (e.g. cookie, accept, and more) are also accepted. Required headers are: Connection, User-Agent, Upgrade-Insecure-Requests.
- userId: Unique identifier within a single request; returning responses contain the userId attribute.
Here’s a sample request containing 4 URLs:
{
"user_key":"7OfLv3QcY5ccBMAG689l",
"URLS":[
{
"URL":"https://www.reddit.com/r/fatFIRE/comments/vnqfx7/how_do_you_use_money_to_automate_the_busywork_of/",
"Headers":{"Connection":"keep-alive","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0","Upgrade-Insecure-Requests":"1"},
"userId":"ID-0"
},
{
"URL":"https://www.reddit.com/r/fatFIRE/comments/vnoxsh/how_do_you_decide_when_to_walk_away/",
"Headers":{"Connection":"keep-alive","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0","Upgrade-Insecure-Requests":"1"},
"userId":"ID-1"
},
{
"URL":"https://www.reddit.com/r/Bogleheads/comments/vnoov7/how_low_will_your_equity_allocation_go/",
"Headers":{"Connection":"keep-alive","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0","Upgrade-Insecure-Requests":"1"},
"userId":"ID-2"
},
{
"URL":"https://www.reddit.com/r/personalfinance/comments/vnk5ja/about_to_turn_40_virtually_no_retirement_savings/",
"Headers":{"Connection":"keep-alive","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10.15; rv:71.0) Gecko/20100101 Firefox/71.0","Upgrade-Insecure-Requests":"1"},
"userId":"ID-3"
}
]
}Step 3. Get the response and download the files
When finished, the API will send a JSON response containing – in our case – four download URLs. Upon receiving the response, notice its attributes: Status (HTTP status) and Link (file download link.) Follow the links to download the corresponding contents.
{
"ID-0":{"status":996,"link":""},
"ID-1":{"status":200,"link":"https://www.domain.com/files/product2.txt"},
"ID-2":{"status":200,"link":"https://www.domain.com/files/product3.txt"},
"ID-3":{"status":null,"link":""}
}Please note that the server stores each file for 20 minutes. The optimal URL count is below 1,000 URLs per one request. Processing 1000 URLs may take 1-5 minutes.
Reddit Scraping with Python
Another method of collecting Reddit data is building a scraper with Python – arguably, the most popular programming language when it comes to web scraping. In this section, we’ll see how to scrape subreddits, extract popular posts, and save this data to CSV files.
❔ Further reading: We have an up-to-date overview of Python web crawlers on our blog – or you can watch its video version on YouTube.
🍲 Further reading: Using Python's BeautifulSoup to scrape images
🎭 Further reading: Using Python's Puppeteer to automate data collection
Install PRAW and Create a Reddit App
To use Python for scraping Reddit data, we’ll need PRAW (Python Reddit API Wrapper), a specialized library that allows us to interface with Reddit via Python. Run this command to install PRAW:
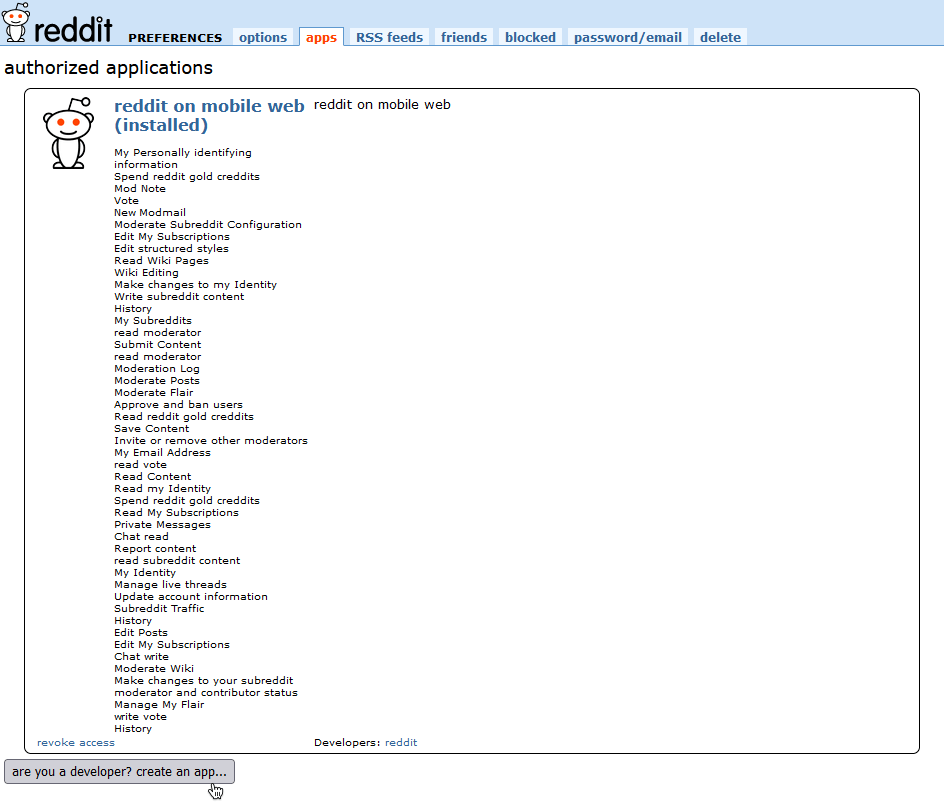
pip install prawWe will wrap our scraper into a Reddit app, which acts as a blueprint for all Reddit bots. To create a Reddit app, head over to the Authorized applications page on your profile and click the “Are you a developer? create an app…” button at the bottom of the screen.
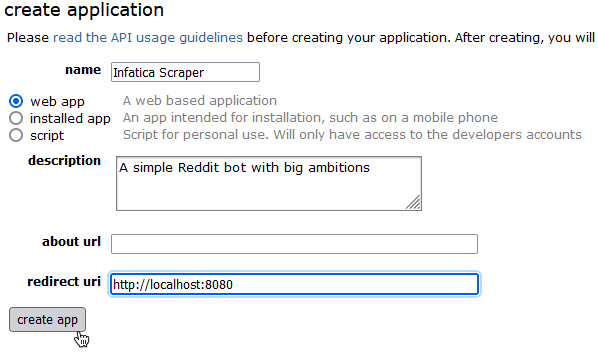
The Create application page will open. Let’s fill in the Name and Description fields; in Redirect URI, input http://localhost:8080.
Upon clicking Create app, you’ll see the overview of your new app. We’re interested in the following values: client_id, secret, and user_agent – we’ll need them later to authenticate our scraper when it connects to Reddit.
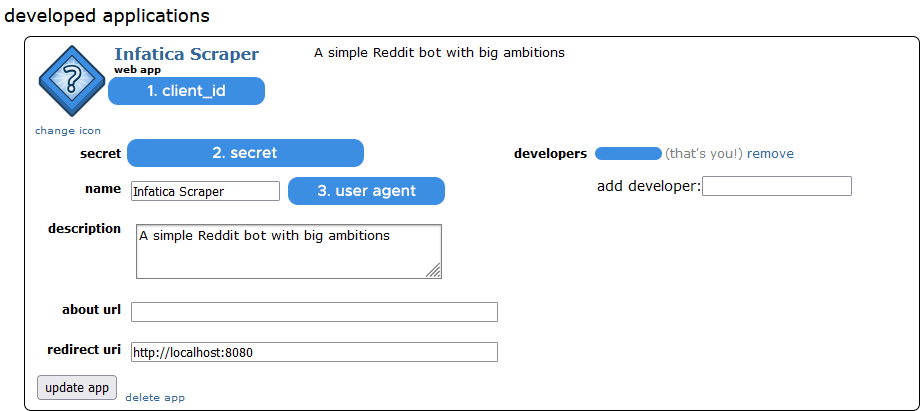
Create a PRAW bot
PRAW supports two types of instances:
- Read-only: Collect public data without interacting with the platform (i.e. if you were a guest user.)
- Authorized: Full interactive functionality that makes Reddit so popular – submitting posts, upvoting/downvoting them, and sending comments.
Reddit’s Terms of Service states that interactive features are reserved for human users. To remain fully-compliant with ToS and avoid account restrictions, we’ll use the read-only instance – it’s perfectly OK for web scraping. This code creates a read-only PRAW bot:
reddit_read_only = praw.Reddit(client_id="", # your client id
client_secret="", # your client secret
user_agent="") # your user agentIf you’re interested in creating an authorized instance instead, add your Reddit username and password values:
reddit_authorized = praw.Reddit(client_id="", # your client id
client_secret="", # your client secret
user_agent="", # your user agent
username="", # your reddit username
password="") # your reddit passwordScrape The Subreddit's Overview
All subreddits share the same post leaderboard structure: Reddit posts are placed in categories like hot, new, top, and controversial. This code will display an overview of the given subreddit, printing its display name, title, and description:
import praw
# Read-only instance
reddit_read_only = praw.Reddit(client_id="YOUR-CLIENT-ID", # your client id
client_secret="YOUR-SECRET", # your client secret
user_agent="YOUR-USER-AGENT") # your user agent
subreddit = reddit_read_only.subreddit("AskNetsec")
# Display the name of the Subreddit
print("Display Name:", subreddit.display_name)
# Display the title of the Subreddit
print("Title:", subreddit.title)
# Display the description of the Subreddit
print("Description:", subreddit.description)
R/AskNetsec is a subreddit dedicated to discussing various cybersecurity topics. Here's the resulting output:
Display Name: AskNetsec
Title: AskNetsec
Description: A community built to knowledgeably answer questions related to information security in an enterprise, large organization, or SOHO context.
Questions on how to get started? Check out the following subs:
* r/SecurityCareerAdvice
* r/NetSecStudents
* r/ITCareerQuestions
Question on issues regarding personal security? Check out the following subs:
* r/Cybersecurity101
Please read and abide by our [Rules & Guidelines](https://reddit.com/r/asknetsec/about/rules)Scrape The Subreddit's Hot posts
R/Bogleheads is a subreddit for discussing John C. Bogle’s (the founder of The Vanguard Group) ideas about long-term investment instead of speculation. Let’s scrape five of its current Hot posts:
subreddit = reddit_read_only.subreddit("Bogleheads")
for post in subreddit.hot(limit=5):
print(post.title)
print()
Alternatively, replace subreddit.hot with:
subreddit.newfor New posts,subreddit.topfor Top posts,subreddit.controversialfor Controversial posts, andsubreddit.gildedfor posts that received awards.
Here's the output from the code snippet above:
Should I invest in [X] index fund? (A simple FAQ thread)
So you want to buy US large cap tech growth stocks ... [record scratch, freeze frame]
How low will your equity allocation go?
I enrolled in my ESPP for Jul-Sep (90 days). 10% will be deducted from every biweekly paycheck. Should I sell the shares immediately after buying them and buy FZROX for my Roth IRA?
Did I make a mistake by allocating 40% bonds for my 66 year old father?Exporting your Data
R/datascience is a subreddit for brainstorming how to extract insights from the data we collect. Let’s parse its top posts and export using Pandas, a Python library for data analysis and manipulation:
import praw
import pandas as pd
# Read-only instance
reddit_read_only = praw.Reddit(client_id="YOUR-CLIENT-ID", # your client id
client_secret="YOUR-SECRET", # your client secret
user_agent="YOUR-USER-AGENT") # your user agent
subreddit = reddit_read_only.subreddit("datascience")
posts = subreddit.top("month")
# Scraping the top posts of the current month
posts_dict = {"Title": [], "Post Text": [],
"ID": [], "Score": [],
"Total Comments": [], "Post URL": []
}
for post in posts:
# Title of each post
posts_dict["Title"].append(post.title)
# Text inside a post
posts_dict["Post Text"].append(post.selftext)
# Unique ID of each post
posts_dict["ID"].append(post.id)
# The score of a post
posts_dict["Score"].append(post.score)
# Total number of comments inside the post
posts_dict["Total Comments"].append(post.num_comments)
# URL of each post
posts_dict["Post URL"].append(post.url)
# Saving the data in a pandas dataframe
top_posts = pd.DataFrame(posts_dict)
top_postsAdd this code to export data from pandas into a CSV file:
top_posts.to_csv("Top Posts.csv", index=True)Here's the output in Excel:

Scrape Reddit Comments
Gabe Newell, Valve Software’s CEO, once held an AMA answering questions about digital products distribution, game development, technology, and more. To parse a post, input the specific URL. This code collects best comments and saves them to a pandas data frame:
import praw
import pandas as pd
from praw.models import MoreComments
# Read-only instance
reddit_read_only = praw.Reddit(client_id="YOUR-CLIENT-ID", # your client id
client_secret="YOUR-SECRET", # your client secret
user_agent="YOUR-USER-AGENT") # your user agent
# URL of the post
url = "https://www.reddit.com/r/The_Gaben/comments/5olhj4/hi_im_gabe_newell_ama/"
# Creating a submission object
submission = reddit_read_only.submission(url=url)
post_comments = []
for comment in submission.comments:
if type(comment) == MoreComments:
continue
post_comments.append(comment.body)
# creating a dataframe
comments_df = pd.DataFrame(post_comments, columns=['comment'])
comments_df
comments_df.to_csv("Top Comments.csv", index=True)
Just like in the previous code snippet, the last line imports scraped comments into Excel – remove it to open this data as a pandas dataframe. Here's the output in Excel:

Keep in mind that Reddit limits the number of comments that can be scraped to 1,000 entries.
Bonus tip: Which user agent to use?
Another important component of error-free web scraping is user agents – special identifiers which tell the target server about the visitor. Reddit specifically asks users to provide unique and descriptive user agents that contain the target platform, a unique application identifier, a version string, and your username as contact information, in the following format:
<platform>:<app ID>:<version string> (by /u/<reddit username>)Here’s an example of a good user agent:
User-Agent: android:com.example.myredditapp:v1.2.3 (by /u/kemitche)
🎎 Further reading: See our detailed overview of user agents in web scraping.
What about the Reddit API?
Many tech platforms with large volumes of data (Meta, Twitter, Google, and so on) offer official APIs, Application Programming Interfaces, which provide a clear understanding of how the platform works. Developers use APIs to build all sorts of products on top of these platforms – a typical example would be a price tracking service for Amazon products.
Reddit is no exception – unlike companies like Amazon and LinkedIn (which discourage data collection and try to prevent it), Reddit is OK with it. Here’s a quick answer, quoting Reddit’s own API documentation: “We're happy to have API clients, crawlers, scrapers, and browser extensions…” However, permission to scrape Reddit comes with some caveats: the full phrase above is actually “We're happy to have API clients, crawlers, scrapers, and browser extensions, but they have to obey some rules.”
Reddit API’s downsides
Authentication: To use the API, you’ll need to authenticate using your Reddit account. This may be a privacy concern for some users, so they may switch to third-party scraping APIs which don’t require Reddit authentication.
Availability for commercial use: While non-commercial and (most) open-source projects can use the API for free, commercial use (... earning money from the API, including, but not limited to in-app advertising, in-app purchases or you intend to learn from the data and repackage for sale.)
requires approval from the company itself. Reddit doesn’t list its API pricing publicly, so it can be presumed that pricing is negotiated on a case-by-case basis. Third-party APIs, on the other hand, are generally more transparent about their fees and conditions.
Limitations: Reddit imposes a set of restrictions on scrapers – most importantly, limiting the request count (60 requests per minute max.) While this is understandable from the server infrastructure’s perspective, 60 requests per minute may be insufficient for larger-scale web scraping projects.
Is it legal to scrape Reddit?

Please note that this section is not legal advice – it’s an overview of latest legal practice related to this topic.We encourage you to consult law professionals to view and review each web scraping project on a case-by-case basis.
🔍 Further reading: We’ve recently written an extensive overview of web scraping legality that includes collecting data from Google, LinkedIn, Amazon, and other tech giants. This section will provide a brief summary.
Data collection is regulated by a number of state-, country-, and region-wide laws, which are typically connected to intellectual property, privacy, and computer fraud regulations. These include:
- General Data Protection Regulation (GDPR) and
- Digital Single Market Directive (DSM) for Europe,
- California Consumer Privacy Act (CCPA) for California in particular,
- Computer Fraud and Abuse Act (CFAA) and
- The fair use doctrine for the US as a whole,
- And more.
Generally, these laws agree that scraping publicly available Reddit data is legal. However, data collection isn’t limited to the process of collecting – using collected data is even more important. If you scrape Reddit and repost this data to another website unchanged, you may be violating intellectual property laws.
To address this problem, the fair use doctrine recommends you to transform collected data in a meaningful way: This way, it will generate new value to its users and constitute a new product in and of itself. In Reddit’s case, you can use its data to build a service that analyzes the user overlap between different subreddits.
Last but not least, Reddit itself is OK with web scraping and just asks developers to follow its guidelines when collecting its data.
What is the best method for scraping Reddit data?
With Reddit’s API available to any web scraping enthusiast, the developer community has created a wide variety of data collection solutions. We believe that Infatica’s Scraper API is the right tool for your next web scraping project:
Millions of proxies & IPs: Scraper utilizes a pool of 35+ million datacenter and residential IP addresses across dozens of global ISPs, supporting real devices, smart retries and IP rotation.
100+ global locations: Choose from 100+ global locations to send your web scraping API requests – or simply use random geo-targets from a set of major cities all across the globe.
Robust infrastructure: Make your projects scalable and enjoy advanced features like concurrent API requests, CAPTCHA solving, browser support and JavaScript rendering.
Flexible pricing: Infatica Scraper offers a wide set of flexible pricing plans for small-, medium-, and large-scale projects, starting at just $25 per month.
Frequently Asked Questions
Yes – it offers an official API for developers to create Reddit scraping solutions. However, keep in mind that there are certain data collection guidelines (e.g. limiting the request count to 60 per minute) you have to follow so as not to get your bot banned.
The API is free for non-commercial use. For commercial projects, defined as
Note that Reddit (generally) merges open source projects with non-commercial ones.
... earning money from it, including, but not limited to in-app advertising, in-app purchases or you intend to learn from the data and repackage for sale, you need to contact Reddit to receive approval to use the API.
Note that Reddit (generally) merges open source projects with non-commercial ones.
Yes: In the code snippet we provided above, specify the subreddit’s name (e.g. montreal) and run the code – you’ll see the subreddit’s display name, title, and description.
You can use a web scraping service to sift through various subreddits, posts, and users – and save this data to a file. There are visual scrapers like browser extensions which offer basic functionality; then there are also command-line scraping utilities which offer more control over the data collection pipeline.
Order a proxy server. Then, enter the proxy's address into your web browser's or system's proxy settings. Once the address is entered, hit OK and then reload the webpage. You should now be able to browse Reddit using the proxy server.
Residential proxy Reddit services provide users with a unique IP address that is tied to their home or residential area. This type of service is beneficial for those who want to remain anonymous when surfing the web as well as protect their personal information.




{kind=link}
{kind=link}