






Article content


Denis Kryukov
12 min read
Data is a prized treasure, so every company wants to obtain it and reap its benefits: better price intelligence, improved lead generation, more leverage in the real estate industry, and so on. To gather data at scale, companies use web crawlers — special software that can do it automatically.
Actually obtaining the data, however, can be an adventure in and of itself — although humans have no trouble reading and understanding information on the web, “robots” (an umbrella term for computer software that performs repeated actions) are less capable. This is why we need special software libraries designed specifically for web crawling.
In this article, we’ll explore what web crawling is, why Python is so great for these purposes, and which Python libraries can be used to get started with web crawling.
A brief overview of web crawling
Let’s explore the meaning of this term first. Web crawling refers to finding, fetching, and storing web links and (some of) their content. Although this process can be manual (i.e. carried out by a human user), a more typical scenario involves using software to automate it — working tirelessly on virtual servers, these software instances are known as “bots”, “crawlers”, or “spiders”.

Interestingly enough, crawlers are helping you on a daily basis — after all, search engines like Google are, on their most basic level, crawlers that find and catalogue website URLs from all over the web. Of course, they also have a plethora of algorithms on top of that — thanks to them, search engines provide relevant web pages to a search query like “rough collie”.
People also use “Web crawling” as a synonym for “web scraping” — but is it correct? In fact, the two terms have different meanings: web scraping has more to do with retrieving and structuring the webpage’s data.
On the difference between “scraping” and “crawling”
On the web, every instance of data has an address, i.e. the information on where to find it. In most cases, this address would be a URL: https://en.wikipedia.org/wiki/Pythonidae, for instance, indicates that the webpage contains information about a family of nonvenomous snakes commonly known as pythons.
Web crawling refers to the process of finding and logging URLs on the web. Google Search, for example, is powered by a myriad of web crawlers, which are constantly (re)indexing URLs (chances are, you found this article thanks to Google’s web crawlers!)
? Further reading: What is the difference between scraping and crawling?
Web scraping, on the other hand, is a more precise process: Its goal is to extract structured information. While web crawling is more general — all URLs are usually saved — web scraping aims to return structured data from specific categories (think of price aggregators.)
Although the two terms do have slight differences in their meanings, they’re still used interchangeably to refer to data gathering process. Additionally, the tools we’ll explore in this article offer both crawling and scraping capabilities.
Wait — why Python?
You may have noticed Python’s surge in popularity over the last 5 (or even 10) years: The majority of companies working with data choose Python as their core technology. The most typical example is, of course, data science, although other areas of tech enjoy Python’s benefits as well.
We’ve seen the data supporting Python’s popularity — now let’s explore the reasons behind it.
Speed — the other kind of speed, that is
Speed can make or break the technology’s popularity, so it’s only natural that programmers often compare Python with other languages:
Naturally, in a race against lower-level languages like C++ or Java, Python lags behind. The criterion here is “speed” — and Python skeptics point out that “Python is slower than other languages, so it’s slow across the board.”
In this case, the terms “slow” and “fast” refer to raw CPU performance, i.e. how fast a command written in a given programming language can be executed. In this regard, Python may indeed be “slow”. However, Python is blazingly fast in other aspects: business speed and time-to-market performance.
Thanks to its code brevity, Python developers spend less time on “meta-work”. By this term, we mean all the extra code the developer has to write to solve the given problem. This finding is supported by a research titled Programming Language Productivity (this link will open a PDF download window), which explores how different programming languages compare against each other, productivity-wise.
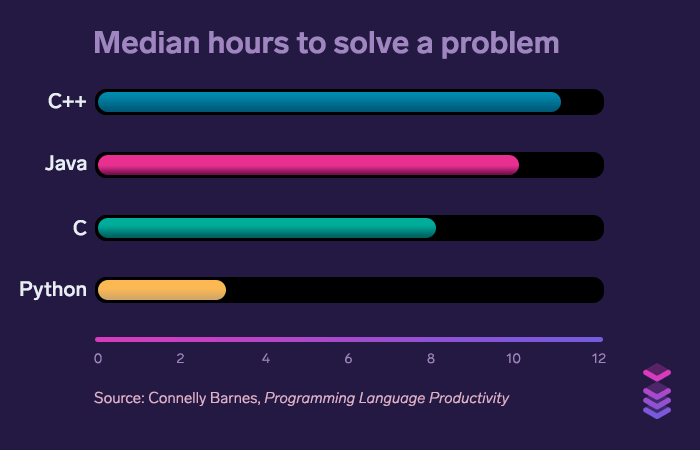
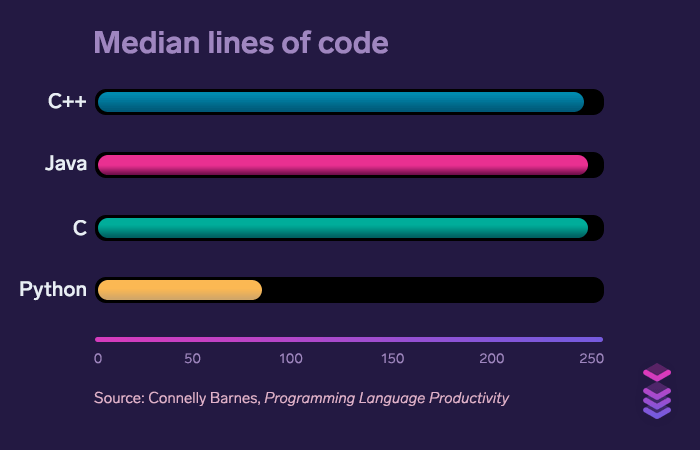
These charts show us that Python saves (arguably) the most valuable resource: developers’ time. A study titled An Empirical Comparison of Seven Programming Languages indicates:
Time spent per line of code is approximately the same in every programming language — which makes Python great productivity-wise. In other words, where Python lacks in the speed of execution, it compensates by the speed of development.
Interestingly enough, CPU bottlenecks are, in fact, quite rare — this is what a study by Google shows. For this reason, judging the given language’s performance by a single factor — namely, how well it utilizes the CPU — isn’t the best strategy.
Other great features
Python wouldn’t become a bastion of productivity and development speed without these features:
The “batteries included” approach. To quote from Python’s official website:
The Python source distribution has long maintained the philosophy of "batteries included" — having a rich and versatile standard library which is immediately available, without making the user download separate packages. This gives the Python language a head start in many projects.
Here are some notable examples:
osmodule to interact with the operating system,remodule for using regular expressions,mathmodule for, well, math,urllib.requestmodule to retrieve data from URLs,datetimemodule to work with dates and times.
The urllib.request module is essential for our needs: It offers features like cookies handling, session management, requests’ history and redirection management, HTTP method calls, and handling response codes and headers.
Also, the combination of being free, open-source, and crossplatform. This ensures that Python is accessible to the widest range of developers possible, making Python web crawlers on GitHub more and more popular.
At this point in the article, you’re probably inspired to try web scraping yourself — and you know there are enough great Python libraries designed for these purposes. In this section, we’ll explore the most popular solutions. Some of them are complex and feature-rich, while others are rather simple.
Scrapy

Although not a library per se, Scrapy is still an important tool for web crawling — it’s a full-fledged framework for web crawling and web scraping. This means that it can be used as a basis for custom web spiders when your project needs are more demanding. As the project’s FAQ page states:
Scrapy is an application framework for writing web spiders that crawl websites and extract data from them.
The “Meet the Scrapy pros” page lists a large number of companies that use Scrapy for their daily needs. Let’s explore these use cases:
- Scraping articles from various news sites
- Scraping job postings
- Data mining for research
- Scrape fashion websites
- Aggregate government data
- Price intelligence
- Scraping geolocation data
- Preloading cache for customer websites, and more.
Although originally designed for web scraping, Scrapy can now handle retrieving data via APIs as well. This is a great upgrade — APIs are, after all, a more preferable way of acquiring website data.
Using Scrapy can be even easier with Portia, a tool designed for visual scraping. Additionally, Portia abstracts much of the complexity associated with web scraping: as the project’s Readme states, it can be used without any programming knowledge required.
The project’s overview page provides various code snippets — they can serve as a helpful example that we can study.
Example code, courtesy of Scrapy's GitHub profile:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text::text').get(),
}
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, self.parse)When to use Scrapy: This library is optimal when you need a custom solution for crawling and scraping HTML pages.
Pyspider

Pyspider is another powerful web crawling system. One of its advantages is the (optional) web-based user interface, which can prove useful to people who prefer graphical interfaces over their command line counterparts. pyspider offers a demo page where you can try it yourself.
❕ Editor note: As of May 26, 2020, the demo page isn't working — but it might work when you're reading this article.
Web scraping pros rarely have only one active project — in most cases, they have to manage a dozen of them. Pyspider addresses this problem by implementing a dashboard, which allows the developer to edit scripts, monitor and manage their current crawlers, and view results.
Pyspider boasts JavaScript support, meaning it’s not restricted to pure HTML pages. JavaScript support is a somewhat complicated feature: With most web crawling libraries, you have to install additional libraries to enable it. A good example is Scrapy, which needs scrapy-splash for JavaScript integration, making the Pyspider vs. Scrapy debate even more complicated.
Pyspider, on the other hand, integrates with Puppeteer, a powerful Node.js library for automation in Chromium-based browsers. This allows pyspider to render JavaScript pages and grab their data correctly.
Another distinctive feature is the focus on crawling rather than scraping. Finally, pyspider supports both Python 2 and Python 3.
Example code, courtesy of pyspider's GitHub profile:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}When to use pyspider: This library is optimal for crawling pages that rely on JavaScript to work properly.
MechanicalSoup

MechanicalSoup owes its prowess to the technologies it was built upon. One such technology is the requests module that we discussed earlier, which is used to retrieve web pages. MechanicalSoup is also based on Beautiful Soup — a famous Python library for extracting data from HTML and XML files.
However, MechanicalSoup developers highlight that this library would be a suboptimal choice if…
- … the target website does not have HTML pages (the
requestsmodule should be used instead.) - … the target website relies on JavaScript (in this case, Selenium would work better.)
Example code, courtesy of MechanicalSoup's GitHub profile:
"""Example app to login to GitHub using the StatefulBrowser class."""
from __future__ import print_function
import argparse
import mechanicalsoup
from getpass import getpass
parser = argparse.ArgumentParser(description="Login to GitHub.")
parser.add_argument("username")
args = parser.parse_args()
args.password = getpass("Please enter your GitHub password: ")
browser = mechanicalsoup.StatefulBrowser(
soup_config={'features': 'lxml'},
raise_on_404=True,
user_agent='MyBot/0.1: mysite.example.com/bot_info',
)
# Uncomment for a more verbose output:
# browser.set_verbose(2)
browser.open("https://github.com")
browser.follow_link("login")
browser.select_form('#login form')
browser["login"] = args.username
browser["password"] = args.password
resp = browser.submit_selected()
# Uncomment to launch a web browser on the current page:
# browser.launch_browser()
# verify we are now logged in
page = browser.page
messages = page.find("div", class_="flash-messages")
if messages:
print(messages.text)
assert page.select(".logout-form")
print(page.title.text)
# verify we remain logged in (thanks to cookies) as we browse the rest of
# the site
page3 = browser.open("https://github.com/MechanicalSoup/MechanicalSoup")
assert page3.soup.select(".logout-form")When to use MechanicalSoup: This library is optimal when you need a rather simple crawling script without any JavaScript support: ticking boxes in a form or logging in to a website.
A few projects built with MechanicalSoup
gmusicapi, an unofficial API for Google Play Music. Although not supported nor endorsed by Google, it boasts an active development team and wide community support. Update 12.05.2020: Google Play Music is set to shut down in 2020.
chamilotools, a collection of tools designed to interact with a Chamilo learning management system.
PatZilla, a platform built for patent search.
Honorable mentions: Other Python web crawlers that might interest you
Cola is similar to Scrapy in its approach: It’s a crawling framework designed for both crawling pages and extracting their data. However, this project hasn’t been updated to Python 3 — and with Python 3’s dominance over Python 2, Cola may be somewhat cumbersome to use.
Mechanize had a similar fate, but a new project maintainer upgraded it to Python 3 in 2019. MechanicalSoup is a descendant of Mechanize, so they share a lot of functionality. However, MechanicalSoup is also lighter: It has 20 times less code lines than its ancestor.
RoboBrowser, on the other hand, is MechanicalSoup’s brother: Both libraries are built upon the requests + BeautifulSoup combo, leading to almost identical APIs. However, MechanicalSoup does have the upper hand when it comes to maintenance activity: RoboBrowser hasn’t been updated since 2015 and doesn’t work correctly on Python 3.7.
demiurge supports both Python 2 and Python 3, but it lacks proper documentation and active development.
feedparser is built to address a specific task: parsing Atom and RSS feeds. For more general web-scraping needs, feedparser isn’t the best option.
Lassie solves another specific problem: retrieving the website’s general information via just one (if you don’t count import lassie) command. This data is returned in a well-formatted dictionary — below is the code for fetching YouTube video info.
Example code, courtesy of Lassie's GitHub Profile:
>>> import lassie
>>> lassie.fetch('http://www.youtube.com/watch?v=dQw4w9WgXcQ')
{
'description': u'Music video by Rick Astley performing Never Gonna Give You Up.\
YouTube view counts pre-VEVO: 2,573,462 (C) 1987 PWL',
'videos': [{
'src': u'http://www.youtube.com/v/dQw4w9WgXcQ?autohide=1&version=3',
'height': 480,
'type': u'application/x-shockwave-flash',
'width': 640
}, {
'src': u'https://www.youtube.com/embed/dQw4w9WgXcQ',
'height': 480,
'width': 640
}],
'title': u'Rick Astley - Never Gonna Give You Up',
'url': u'http://www.youtube.com/watch?v=dQw4w9WgXcQ',
'keywords': [u'Rick', u'Astley', u'Sony', u'BMG', u'Music', u'UK', u'Pop'],
'images': [{
'src': u'http://i1.ytimg.com/vi/dQw4w9WgXcQ/hqdefault.jpg?feature=og',
'type': u'og:image'
}, {
'src': u'http://i1.ytimg.com/vi/dQw4w9WgXcQ/hqdefault.jpg',
'type': u'twitter:image'
}, {
'src': u'http://s.ytimg.com/yts/img/favicon-vfldLzJxy.ico',
'type': u'favicon'
}, {
'src': u'http://s.ytimg.com/yts/img/favicon_32-vflWoMFGx.png',
'type': u'favicon'
}],
'locale': u'en_US'
}As we can see, Lassie provides video description, keywords, images, and so on. Alternatively, you can use this library to fetch article data (including description, title, locale, images, etc.) or all images from the given web page.
Selenium, compared to other tools we explored earlier, is somewhat of heavy artillery: It contains a full-fledged web browser, enabling full JavaScript support. However, Selenium’s rich functionality introduces some overhead: this solution would be an overkill for basic web scraping/crawling.
Conclusion
Web crawlers may seem complicated, but we encourage you to try one of them ourselves. Last but not least, you’ll also need proxies: without them, anti-scraping systems will detect that your web crawlers aren’t genuine users — and they’ll block them.
Residential proxies address this problem by masking your (or, in this case, your web crawlers’) identity, so the target server sees proxy users as real people from any country, state, and city they prefer. Naturally, this makes web crawling significantly easier: You’re running a much lower risk of getting banned or encountering CAPTCHAs.
Frequently Asked Questions
You can choose from a wide array of Python web crawling libraries: Scrapy, Pyspider, Mechanicalsoup, and more. Each library has its pros and cons: You should pay extra attention to their JavaScript rendering capabilities, as the content of many sites nowadays is dynamic.
As covered in our web scraping legality guide, crawling websites is legal because, in most cases, crawling involves access to website's public portion of data. Still, you cannot simply republish or sell crawled data without any meaningful changes – this would clearly be an intellectual property violation.
Web crawlers index the website's content; this data can later be collected and used for price aggregation, SEO, brand protection, marketing, academic research, uptime and performance tracking, corporate data protection, cybersecurity, and more. Last but not least, proxies can be a personal privacy tool.
Absolutely: Python is arguably the most popular language for building crawlers. Its popularity stems from ease-of-use and a wide choice of in-built libraries for working with data, system, and more.




{kind=link}
{kind=link}