






Article content


Vlad Khrinenko
7 min read
Data collection offers numerous opportunities for businesses: They can grow faster and make better informed decisions — and more companies are adopting data collection to seize these opportunities.
In our previous web scraping tutorials that covered cURL and Puppeteer, we explored how to use these utilities for web scraping — and we focused on retrieving textual data like the top list of Hacker News articles. However, the web has another essential component to it — visual data, which includes components like images and videos.
In this article, we'll be scraping images in Python and BeautifulSoup: We’ll learn more about how images work on the web, why people choose Python as their data collection instrument, and which code snippets you can use to scrape images from websites yourself.
Why choose Python?
As outlined in our overview of Python web crawlers, Python is a great choice for data collection projects — and many data science professionals seem to agree, preferring Python components over their R counterparts.
The most important factor is (arguably) speed. This may confuse you: Python isn’t a low-level language like C++ or Java, so its computational speed is much slower. However, Python is incredibly fast in terms of development speed, saving precious man-hours thanks to its code brevity.
Another benefit that Python offers are libraries, smaller pieces of ready-to-use Python software designed for specific actions. Being open-source, Python has both built-in and external libraries for interacting with the OS, using regular expressions, math, dates, time, and more.
Web scraping legal disclaimer
Although we’re not setting up a massive web scraping project here, we should still make sure to not overstress the website we’re collecting data from: Sending too many requests is dangerous because it may:
- Put too much pressure on the web server, causing an unintended DDoS attack, and
- Trigger anti-DDoS systems which will block your IP address, preventing you from accessing the website.

The legality of web scraping is a complicated topic: As of July 2021, there’s still no easy answer like “Yes, web scraping is perfectly legal.” In our overview of web scraping’s legality, we came up with the following guidelines:
- If there is an API for data collection, use it,
- Respect the terms of service,
- Respect the website’s
robots.txt(a special document that outlines which data can be collected,) - Make sure that the data is not copyrighted, and
- Don’t publish gathered information without the permission of its owner.
When you’re just starting out with web scraping, you may have a hard time understanding the limits you should set for your scraper — following these rules will help you avoid problems with data owners.
The setup
As mentioned above, Python libraries are essential for scraping images: We’ll use requests to retrieve data from URLs, BeautifulSoup to create the scraping pipeline, and Pillow to help Python process the images. Let’s install all three libraries with a single command:
pip install requests beautifulsoup4 PillowThen, we need to choose the web page we want to collect images from. To keep things simple, let’s use one of our articles that covers the difference between web scraping and web crawling — it has a few images we can try and scrape.
This first code snippet imports the necessary libraries. shutil will help us store data within files:
from bs4 import BeautifulSoup
import requests
import urllib.request
import shutilHow images are organized in HTML
The web uses several languages to put its content together: CSS handles the visuals, JavaScript enables interactivity, and HTML organizes everything. Images are marked by the <img src> tag-attribute pair, which Python will need later. We can open our test article and right-click any image to inspect it and see which tags mark it:
Here’s the whole HTML tied to a random article image: <img src="https://infatica.io/blog/content/images/2020/09/what-is-web-crawling.png" class="kg-image" alt="Web crawler indexes general web content">. Although it contains several attributes, we’re only interested in the following one: class="kg-image" as it denotes that the given image is an article illustration and not a decorative element.
Adding BeautifulSoup components
Let’s put the idea above into code:
url = "https://infatica.io/blog/web-crawling-vs-web-scraping/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
image_links = soup.find_all("a", class_='entry-featured-image-url')In the code snippet above, we’re storing each article illustration in an improvised list. If we run print(image-links), we’ll get the following list:
<img src="https://infatica.io/blog/content/images/2020/09/what-is-web-crawling.png" class="kg-image" alt="Web crawler indexes general web content">
<img src="https://infatica.io/blog/content/images/2020/09/what-is-web-scraping.png" class="kg-image" alt="Web scraper indexes specific web content">
<img src="https://infatica.io/blog/content/images/2020/09/web-scraping-for-market-research.png" class="kg-image" alt="Web scraper parses price data">
<img src="https://infatica.io/blog/content/images/2020/09/web-scraping-for-machine-learning.png" class="kg-image" alt="Web scraper parses user comments">
<img src="https://infatica.io/blog/content/images/2020/09/web-scraping-location-restriction-2.png" class="kg-image" alt="Websites restrict access from users from certain regions ">Next, we need to extract direct image links and store this data in a list:
image_data = []
for link in image_links:
image_tag = link.findChildren("img")
image_info.append((image_tag[0]["src"], image_tag[0]["alt"]))The image_links list now contains all links we need — we can write a function to download images from the list:
def download_image(image):
response = requests.get(image[0], stream=True)
realname = ''.join(e for e in image[1] if e.isalnum())
file = open("./images_bs/{}.jpg".format(realname), 'wb')
response.raw.decode_content = True
shutil.copyfileobj(response.raw, file)
del response
for i in range(0, len(image_info)):
download_image(image_info[i])Finally, we can improve our code by creating a class, making it more modular. This is the end result:
from bs4 import BeautifulSoup
import requests
import shutil
class BeautifulScrapper():
def __init__(self, url:str, classid:str, folder:str):
self.url = url
self.classid = classid
self.folder = folder
def _get_info(self):
image_data = []
response = requests.get(self.url)
soup = BeautifulSoup(response.text, "html.parser")
links = soup.find_all("a", class_= self.classid)
for link in links:
image_tag = link.findChildren("img")
image_data.append((image_tag[0]["src"], image_tag[0]["alt"]))
return image_data
def _download_images(self, image_data):
response = requests.get(image_data[0], stream=True)
realname = ''.join(e for e in image_data[1] if e.isalnum())
file = open(self.folder.format(realname), 'wb')
response.raw.decode_content = True
shutil.copyfileobj(response.raw, file)
del response
def scrape_images(self):
image_data = self._get_info()
for i in range(0, len(image_data)):
self.download_image(image_data[i])Ensuring easier web scraping with proxies
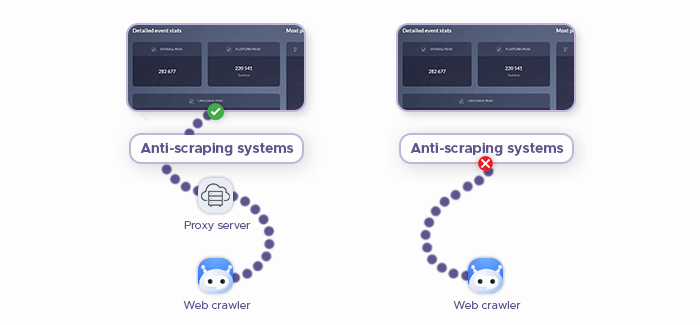
Even though our project is relatively small-scale, we can still run into some problems when scraping images: Many web services have anti-scraping systems in place which detect and block crawlers. Why even install these systems in the first place, though?
Well, some web scraping enthusiasts don’t follow the guidelines we outlined in the “Legal Disclaimer” section, overloading web servers and causing quite a stir among data owners — and their response is to restrict web scraping altogether. These measures may include CAPTCHAs and IP blocks.
Proxy servers can address this problem by masking your IP address, making it harder for websites to detect that your crawler is, in fact, not a regular human user. Residential proxies are great at bypassing anti-scraping mechanisms: As their name suggests, they're sourced from real residents of various countries.
Add this code snippet to enable proxies in BeautifulSoup, replacing the IP placeholder IP address (10.10.1.10) and port (3128.)
import requests
proxies = {"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080"}
requests.get("http://example.org", proxies=proxies)Frequently Asked Questions
There are a few different ways you can go about pulling all images from a website. One way would be to use a web scraper library, like Scrapy or Cheerio. You can also use the Google ImagesAPI. Or, if you're feeling really ambitious, you could write your own image crawler.
One way is to use BeautifulSoup with a proxy: This will allow you to bypass the website's protection and copy the image. Another way is to use a screen capture tool like Snagit. This will also allow you to bypass the protection and copy the image.
One way is to use the Selenium web driver. Selenium can be used to automate web browsers in order to do things like fill out forms or scrape data from sites that require a login. Alternatively, use Ghost.py, which is a headless browser written in Python that can be used for scraping Javascript-heavy websites. Yet another approach is to use Google's own custom search API, which lets you perform up to 100 searches per day for free.
If you want to copy an image from a website, you can try using a browser extension or software like Snagit. Once you have the image saved, you can then crop it or edit it as needed.



{kind=link}
{kind=link}