






Article content


Denis Kryukov
8 min read
The rise of web technologies has reinforced a millennia-old lesson: information is an incredibly important asset. With the majority of Earth’s population owning an electronic device (smartphone, laptop, tablet — you name it), we’re contributing immense volumes of data via every purchase or movement.
This data has huge potential: It can be used for academic research, cybersecurity testing, performance tracking, and more. Of course, the most widely-used application of data is commercial: The last decade has seen the rise of companies with data as their main product.
In any case, you can leverage web scraping to bring even more value for your business — but how can you do it ethically and responsibly? In this article, we’ll try and answer this question (short answer: Yes, you can.)
Disclaimer: This article provides best practices, but not guidelines or legal advice. Each web scraping project is unique, so it’s best to exercise due diligence.
A quick overview of web scraping and web crawling
Web scraping is the process of extracting structured information from the web.
“The web” is an entire universe of unique content: static and dynamic sites, free and commercial services, simple HTML pages and full-blown web apps… Although each website is unique, they all follow certain web standards to enable standardization — this way, users know what to expect when interacting with the web.
This standardization makes web scraping possible: We know, for example, that table data is normally stored inside the <table> HTML elements. Therefore, if we want to scrape table data from the given website, we need to target the <table> element.

Naturally, web scraping is automated via specialized software (called “web scrapers” or “bots”.) This enables web scraping at scale: Given enough resources (i.e. servers) and understanding of web development (to fine-tune the scraping process for some websites), the sky’s the limit.
Editor’s note: Throughout this article, we’re using the term “web scraper” to also mean “a person/group of people who gather data from the web”, so don’t be surprised to see a sentence like “Web scrapers have families to feed.” :)
Does “web scraping” mean the same as “web crawling”?
You might notice that some articles use the terms “web scraping” and “web crawling” interchangeably: Our latest overview of python web crawlers, for instance, actually covered both scrapers and crawlers. Although the meanings of these two terms are similar, they aren’t identical: Web crawling’s goal is finding and logging URLs, but not data.
For the purposes of this article, we’ll use the term “web scraping” to mean a more general process of acquiring both data and URLs.
❔ Further reading: Web Crawling vs. Web Scraping: Understanding the Difference
Web scraping use cases
In the introductory section, we mentioned a few use cases of web scraping. Let’s cover them in greater detail:
Aggregators aim to collect information from various data sources and structurize it, bringing value to their users in the form of convenience. You know the typical examples of aggregators, of course: Google Flights, TripAdvisor, Booking.com, etc.
Web scraping is also instrumental in market research in general: Businesses can learn more about their competitors via pricing intelligence and other data like target audiences, product summaries, and so on.
For academic research, the more data, the better: The research’s results are likely to be more factually correct and precise this way. The same logic applies to machine learning in particular.
Web scraping issues
However, automation of web scraping introduces certain problems: Website owners (and data owners in general) often object to collection of their data. But why? Some reasons are:
- Web scraping can be used to get pricing intelligence — and some companies want to prevent their competitors from gaining it.
- Similarly, it can also be used to infringe copyright (e.g. steal content.)
- Web scraping bots can overload target servers’ infrastructure by sending too many requests. This can produce an undesirable, DDoS-like side effect: The target server fails under pressure, cutting off access to both real users and web scrapers themselves.
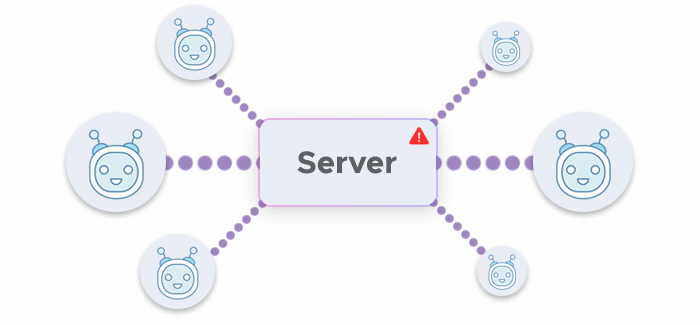
As we can see from the examples above, web scraping can be a force for good — but a force of evil as well, especially when malicious management or mismanagement of scrapers leads to copyright infringement or other problems.
Trying to solve the problem in court
Over the years, data owners and web scraping enthusiasts have debated whether web scraping is legal. Seeing that the discussion isn’t working out, data owners set up anti-scraping systems: typical examples include blocking IP addresses and using CAPTCHAs. While these measures do stop some scrapers, proxy servers can negate their effectiveness.
Seeing that these systems aren’t working out either, data owners take their claims to court: They sue web scraping-focused companies in hopes that US judges will finally render web scraping illegal — but many years and many cases later, there’s still no legal consensus.
The article titled Web Scraping and Crawling Are Perfectly Legal, Right? by Benoit Bernard provides a great overview of numerous legal cases that involved web scraping. The conclusion that “This is a grey area” is all too common: As shown by the legal practice, excuses like “Come on, it’s not like I’m robbing them — I’m just parsing the information that they themselves made publicly available!” or “This is fair use!” don’t fare well in court — and sometimes, web scrapers lose the case.
❔ Further reading: How Legal Is Web Scraping — and How to Avoid Legal Problems?
The same article also provides the greatest piece of advice regarding the legality of web scraping: “Finally, you should be suspicious of any advice that you find on the internet (including mine), so please consult a lawyer.”
Ethical web scraping guidelines

In most scenarios, it is possible to gather data ethically — you just need to show respect for data ownership. This would mean establishing the following relationship:
- Data owner provides the terms according to which their data may be scraped.
- Web scrapers follow these terms.
- Both parties sleep better at night, knowing that they’ve avoided unnecessary confrontation.
Communication
Like most problems in life, the problem of “How do I approach scraping this data without causing too much chaos?” can be solved via communication. All too often, the conflict between the data owner and the scraper arises when the latter doesn’t take their time to set up a proper (business) relationship with the former. How to address this issue?
You can reach out to the data owner to explain your intentions. Here’s a framework: “Hello, Example Company team! I’m currently conducting research on the effects of COVID-19 on retail. To get a better picture of these effects, I’m analyzing the changes in price data across the US markets. I plan to scrape your price data from the following time period: January 2020-June 2020 and hope you’re okay with it. I will be careful not to overload your servers: Here are the planned crawl rate and other technical details… Kind regards, Jonathan K.”
In this case, you will provide some personal info by introducing yourself, but unless you’re breaking the website’s terms of service in a dangerous way, it’s not a problem.
Try to use APIs
An API (Application Programming Interface) is a system that, among other things, defines how to access the company’s data correctly (i.e. without wrecking havoc.) For all intents and purposes, an API is “the right way to do web scraping”:
- It’s (usually) well-documented, providing the necessary information and technicalities. Some APIs even feature FAQ sections and guides to help developers conduct web scraping more easily.
- It allows for more advanced automation.
- It offers data that may not be publicly available.
- It indicates that interacting with the company's data is allowed, so a conflict is less likely.
Interestingly enough, it’s not uncommon for companies to go the opposite direction — stop offering APIs, that is. A good example comes from Instagram: As the platform grew in popularity, its API was ripe for abuse by black-hat marketers, so the company severely limited the API functionality.
Consult ToS
The website’s terms of service (ToS) and other similar documentation might seem like a boring read, but they should be your go-to source for most questions related to web scraping. In this category, terms of service is the most informative document: More often than not, it details all technical and legal details you’ll need to avoid causing trouble. Let’s turn to Facebook for an example: Here are their ToS outlining the special terms for automated data collection.
Consult robots.txt
robots.txt is a website file that indicates which pages may be requested from the website. Its primary goal is preventing crawlers from putting too much pressure on the server infrastructure. This is achieved by providing parameters like crawl-delay: Together, they define the acceptable crawl rate (with 1 request per 10-15 seconds being a good compromise.)
As web scraping experts point out, robots.txt and ToS are separate documents: You may be tempted to only follow the former and say: “Well, my web scraping activity is legal because I respect the website’s robots.txt!” However, it doesn’t mean that you’re exempt from ToS: While robots.txt can be compared to guidelines, ToS is more similar to a legally binding document.
Frequently Asked Questions
The best way involves encountering as few web scraping roadblocks as possible: If your bot is constantly encountering CAPTCHAs and IP bans, you should try residential proxies and follow the website’s robots.txt more closely to better comply with its conditions.
There is no definitive answer to this question – it depends on your needs and preferences. Some people prefer Python for web scraping because of its relative simplicity and flexibility, while others prefer R for its wealth of built-in data analysis tools. Ultimately, the best tool for the job depends on your specific requirements.
Be aware of the legal restrictions in your country or region. In some cases, you may need to get permission from the website owner before crawling their website. Also, make sure you're not violating any terms of service agreements by scraping data from websites. Many websites include clauses in their TOS that prohibit data scraping or spidering.
Home editions of web browsers cannot be used to automate web scraping, so developers use their specialized versions instead: Headless browsers lack the graphical interface and are controlled via terminal commands. Some popular headless browsers are Headless Chrome, Headless Firefox, and PhantomJS.
Yes: The most common way is by detecting automated requests from bots, which is done via checking the user agent string of the request and comparing it to a list of known bot user agents. If the request comes from a bot that is not on the list, then the website knows that the request is coming from a scraper and will block or throttle the IP address.



{kind=link}
{kind=link}