






Article content


Jovana Gojkovic
6 min read
Price aggregators offer an incredibly useful service — they allow people to find the best price for the product they’re looking to buy. However, the sellers of those goods aren't particularly fond of this idea, and they’re easy to understand: Why would they want their prices to be compared to the prices of their rivals, especially if it doesn’t help them to win the competition?
E-commerce websites deploy a myriad of systems to protect their data from being scraped, which creates significant obstacles for price aggregators. However, there is a very simple solution — residential proxies. In this article, we'll explore how price aggregators can use them to improve their services.
How exactly are sellers protecting their websites from data gathering?
It’s extremely hard to keep the price data up-to-date for the aggregator if performing this activity manually. That’s why these services use bots (often called web scrapers) that gather and process price data automatically. Thanks to this instrument, price aggregators can simply "delegate" the task to a web scraper, programmatically describing which exact data to acquire. In a short while, they get clean ready-to-use results.
This sounds quite nice and easy, but the automation of the data gathering process is simultaneously a disadvantage: It allows websites to detect this activity and block scraper bots. Here's the issue: The activity of scrapers is very easy to spot because they’re sending way too many requests to a single server within a short amount of time. Obviously, a user that's sending dozens of requests every second is bound to be running some sort of automation.
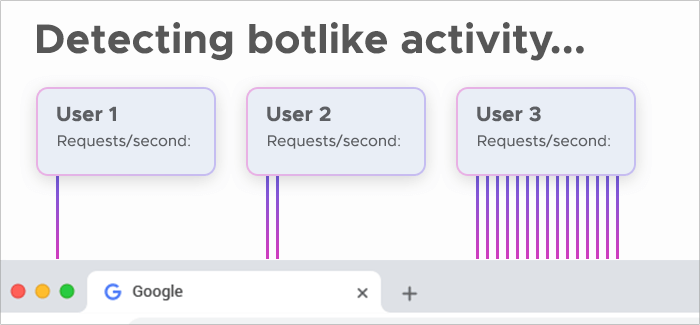
Moreover, all these requests typically come from the same IP address. That’s not the kind of behavior a regular user would show, clearly indicating bot activity.
Therefore, all the server needs to do is to simply deny access to an IP address that sends bot-like requests. That’s how e-commerce websites try to keep price aggregators away — and in most cases, they succeed in this mission. Web scrapers quickly catch bans from online stores, and then the whole process gets jammed.
Another trick sellers might use is data cloaking: They would show different prices for users from different locations. It makes the job of price aggregators much more complex as they need to check the prices from various locations to make sure they don’t fetch their users false data. As residential proxies change your IP, they also let you pretend you’re located in another area. Use this advantage to confirm the prices.
How can residential proxies help with data gathering?
Quality web scrapers allow users to alter all the data packets that outcoming requests pass to the destination server. You can supply the bot with a library of cookies and headers so that it can apply a new bit of data to each request.
Also, you can supply a scraper with proxies that will change the IP address of a request. Thus, all the inquiries sent by a bot to the destination server will look like those that real users would send. This will let a scraper gather required data without any issues or delays.
How do proxies work?
Proxy is a device or server which the user can reroute the connection through to hide their real IP address. Then, the proxy applies its own IP to the traffic, and the destination server doesn’t see the user data — only the information that belongs to the proxy. Thus, using this tool you can mask your real IP address to remain anonymous, change the location, or, in the case with price aggregators, make the scraper’s requests look authentic.
Why residential proxies?
If you’re not familiar with differences between kinds of proxies, you might want to opt for data center ones since they’re cheaper. As their name suggests, data center proxies are servers that are located in a data center. They will change your location and IP address, but the destination server will see that you’re using a proxy. This might be a problem for web scraping as your activity will still look rather suspicious.
🚲 Further reading: What Are Datacenter Proxies and When You Should Use Them
Residential proxies are real devices that use IP addresses issued by an internet service provider. They are a bit more expensive than their data center counterparts, but this proxy type will make you appear like a real resident of any country you choose.
In other words, if you apply residential proxies to your scraper's requests, its activity will look like the behavior of real human visitors who are just browsing the website. Thus, you can enjoy smooth data gathering without interruptions.
🚗 Further reading: Residential Proxies: A Complete Guide to Using Them Effectively
What are other tips that can help you remain undetected?
In most cases, proxies won’t be enough. As price aggregators improve their data gathering techniques, sellers keep up with these advancements creating new ways to protect their websites from this activity. That’s why you should do a bit more than merely use proxies.
Keep the pace natural
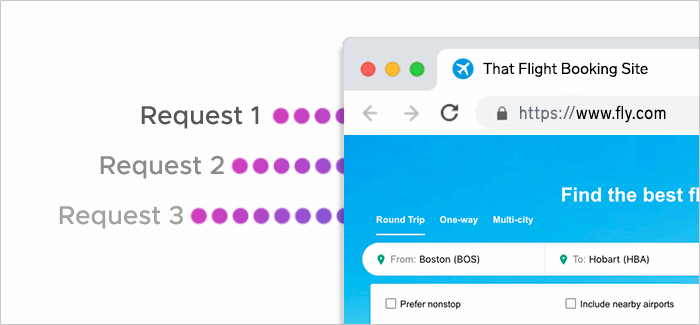
Scrapers can send hundreds of requests within a second, but such activity will definitely seem bot-like even if you apply proxies. Moreover, the destination server might think it’s under a DDoS attack, and then the anti-bot mechanisms will get triggered. It’s better to go slower to mimic the activity of real users.
You might think that reducing the number of requests per second will slow data gathering down, but in fact, this rule will help you accelerate it because you will lower the risk of getting blocked or overwhelming the server.
Make a scraper stop if it encounters 403 or 503 errors
If you do this, its activity will appear natural to the destination server. Users don’t frantically reload the page if they see an error — they simply leave the website and maybe try accessing it again later. Your scraper should do the same, otherwise, the site will understand it's dealing with a bot, and you’ll get banned.
🚦 Further reading: How to Solve Proxy Error Codes
Set up headers
User-agent and other headers show websites that they’re dealing with a real user. There are many libraries with headers on the internet, so it will be effortless for you to find one. Simply supply your scraper with it and set it up so that it changes headers for each request along with IP addresses.
Allow the scraper to accept cookies
Most users will accept cookies when they visit a website. It’s a natural behavior you should adopt for your data gathering process. Good scrapers can accept cookies — you just need to turn this feature on.
Conclusion
Residential proxies solve the main issue price aggregators face allowing them to gather information more efficiently. However, there are other nuances you should pay attention to. If you follow the tips from this article and use proxies for scraping, you will significantly improve the data acquisition.
Frequently Asked Questions
Price scraping is a technique used to automatically collect prices from a given set of websites. Generally, price scraping involves the use of computer code (usually a script or bot) to search for and extract prices from web pages. The collected data can then be used to create price comparisons, track price changes, or simply to have an up-to-date list of prices for a given product or service.
This involves finding and targeting potential customers who are not already reached by other sales channels.
This can be done through various methods such as web scraping, data scraping, or email scraping. Basically, it involves extracting contact information from publicly available sources and then reaching out to them in order to create a sale.
For example, you run an online store that sells consumer electronics. In order to keep your prices competitive, you regularly check the prices of similar products at other stores using a price scraper. If the average margin for these products is 10%, and you're able to sell 100 items per day thanks to your price scraping, then you're potentially looking at a profit of $1,000 per day.
There are a few ways to make a scraping bot. One way is to use a code editor like Python or Java, and then use libraries like Beautiful Soup or Selenium to help with the scraping process. Another option is to use online tools that allow you to create scraping bots without any programming knowledge. Finally, you can also hire a developer to create a custom scraping bot for you.





{kind=link}
{kind=link}