






Article content


Jan Wiśniewski
9 min read
Bots seem to be everywhere nowadays. They’re the cornerstone of search engines, but also they’re used for numerous other needs. So what is a bot? Is it legal to use this tool? What kinds of bots are there, and how can you benefit from using them? In this article, we’ll do our best to answer all these questions in the smallest detail.
What are bots?
First things first, let’s define this term. As the word suggests, it's a short version of the word “robot”.
A bot is a tool that works based on a certain algorithm that was created for a specific purpose. In other words, it’s just a software program that can perform some repetitive task to speed up processes and take the load off our shoulders.
Humans are generally not very good at performing repetitive tasks that don’t require creativity. Let’s be honest: We’re not very eager to do such mundane activities as filling in numerous forms, visiting web pages, gathering data from them, and so on.
That’s why bots were created — they can do these tasks perfectly well without complaining about how boring it is to do them. In data science, natural language processing engineers can even create advanced bots can even write comments or hold conversations with people.
Is it legal to use bots?
Bots themselves are neither legal nor illegal: It’s the activity someone performs using bots that can fall in either of these categories. For example, if the person who is using a bot to gather data from websites ignores the terms of use or robots.txt of a site, or the wishes of its owner, this activity will violate the privacy of a website owner thus becoming illegal.
⭐ Further reading: How Legal Is Web Scraping — and How to Avoid Legal Problems?
Another example of an activity that will be considered malicious is when a person overwhelms the target server with requests the bot sends. This results in a website or an app becoming unavailable. Therefore, the desire to gather data as fast as possible turns into an illegal action because it causes damage to the website or the app.
That’s the reason why most webmasters implement anti-bot tools that would protect the server from such an activity. These measures can’t really tell a malicious bot from a good one apart. Consequently, even those who are using bots with good intentions and care about the privacy of others and the performance of the server will face difficulties because of anti-bot protection.
The mechanics of a bot
A bot is a set of algorithms that follow a certain purpose. For instance, these algorithms can be aimed at gathering specific bits of data from websites. Or the algorithms could be directions that will allow a bot to talk to humans. So the actions a bot can perform depend on the algorithms that were written for it.
Also, there are different levels of complexity of bots. Even a chatbot can come with a different set of features. Simpler ones can just allow a human to choose from set options, while more advanced bots can handle quite detailed conversations understanding natural speech. The latter are usually created with the help of machine learning — just like bots that can understand what’s in a picture, for example.
A few technical details
Bots are not just some add-on components — they’re standalone programs that can access the internet if needed to perform target actions. It means that a bot you’re using to gather data from websites won’t be doing that through your browser. It will perform this activity through its own headless browser.
A headless browser, as the name implies, is a special piece of software: It lacks components ("head") that make browsing easy for regular users — a graphical user interface, for example. Headless browsers, on the other hand, are managed programmatically (via scripts), making them text-based.
👷♂️ Section under construction: We're preparing a detailed article on headless browsers. Once ready, it'll be linked here. Check back soon!
What about malicious bots?
While the lawfulness of bots is more defined by the goals for which they’re used, there are some examples of objectively malicious bots created for harmful activities. Some automated tools are aimed at tasks like detecting pictures with cats among others, and that’s an example of a "good bot". Yet, some are created to perform malicious tasks such as:
- Sending spam,
- Performing DoS and DDoS attacks,
- Click fraud,
- Credentials stuffing, and/or
- Stealing data
The statistics show that,
In 2019, 37.2% of all traffic on the internet wasn’t generated by humans, but by malicious bots.
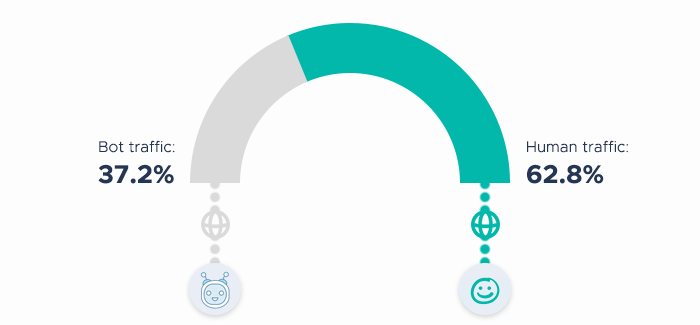
So they’re rather widely-spread, and their number grows constantly.
Different types of bots
Depending on the type of activity a program needs to perform, bots are divided into several categories that describe their purpose. By looking at the kinds of these tools, you will also see different use cases for bots. Of course, it would’ve been very difficult to mention every single type that exists, so we will talk about the most popular ones.
Web crawlers
You could hear about these bots working at the core of search engines. Web crawlers are also called spiders. They’re meant to crawl through web pages, detect the theme and the purpose of the content to catalog and index these pages. As a result, the search engine will be able to fetch users exactly the websites that could provide them with the information they’re seeking.
🐍 Further reading: An Extensive Overview of Python Web Crawlers
Web crawlers download HTML, JavaScript, CSS, and images to analyze the content on the page. Webmasters can tell crawlers which pages to process in the robots.txt, a special file located among other files of the website.
Web scrapers
Scraper bots are more advanced crawlers. They can not just gather and process data, but also extract particular bits of information, transform and organize them in a way that will be easy for a human to work with. Web scrapers are used for gaining business intelligence, marketing, and research purposes, and other needs — data gathering has numerous use cases and benefits.
🧭 Further reading: Web Crawling vs. Web Scraping: Understanding the Difference
Monitoring bots
Similarly to crawlers, these bots will go through the website focusing on the loading speed and other factors that could indicate issues in the system. If such a bot finds any problems, it will tell a webmaster about it. Monitoring bots simplify server maintenance by constantly looking for issues so that a human doesn’t need to do that. Then all the administrator needs to do is to fix the problems the bot has found.
Chatbots
Such tools can help a human find or enter the required information by either offering them preset options or simulating a conversation. The capabilities of chatbots depend on their complexity. There are examples of such bots that can hold quite meaningful conversations with humans. Today, they’re often used to help people solve their psychological issues since bots are good at detecting patterns, even in our behavior.
Spambots
These bots are an example of malicious ones. They gather emails and then send unwanted or unsolicited information to recipients. Also, such emails might contain phishing or malware software that will let hackers get even more data or profit.
DoS and DDoS bots
These types are intended to perform DoS and DDoS attacks. They will send loads of requests to the target server thus overwhelming it and making it go down or at least weakening the defense measures. Obviously, it’s also a malicious type of bots.
Download bots
These are considered to be malicious but they don’t deal with any direct harm to users. Download bots would download applications from Play Store, Apple Store, or other app stores to increase the popularity of an app. The application the bot downloads could be malicious.
How can servers detect bots?
As mentioned earlier, because of malicious bots, webmasters often implement anti-bot measures to detect and block traffic coming from such programs. There are numerous ways to detect bot-like activity and stop it.
Servers recognize bots by:
- Suspicious or repeating IP address (as the bot will send lots of requests from the same IP, its activity won’t look natural.)
- The lack of headers and cookies.
- Weird unnatural browsing patterns.
- An unnaturally high number of requests.
The most popular anti-bot measures are:
- CAPTCHAs,
- Defining rules in robots.txt,
- Checking browser fingerprints to detect whether a headless browser is used,
- Special tools that detect bots, and
- Blocking frequent requests that come from the same IP
How do anti-bot measures impact scraping?
The efforts of webmasters to keep bots away significantly impact the job of those who just want to gather data with positive intentions. Yet, every problem finds its solution, and there already are scrapers that can pretend to be humans so well that it’s nearly impossible for anti-bot tools to set them apart from real users. In their turn, webmasters respond with even more layers and more complex measures against bots.
This makes web scraping even more difficult to execute without getting blocked. While there are websites that allow data gathering if you follow certain rules, others will forbid this activity at all.
How to keep a bot from getting blocked?
Since there are so many anti-bot measures, you need to have a complex approach to scraping. First of all, you can invest in an advanced scraper that can solve CAPTCHAs and imitate human activity well. Just supply it with header libraries if needed and you’re set to go.
Another tool to invest in is proxies. They will change the IP address for your scraper so that it can send requests from different IPs. You should opt for residential proxies as they are IPs that are real and belong to existing personal devices. Therefore, when residential proxies are applied, the activity of your bot will look like the activity of a real resident of a certain location. Then the chances that a target website suspects something become very low.
❔ Further reading: What Are Proxies? An Overview of How They Work and Why They're Important
❔ Further reading: How Residential Proxies Simplify Data Gathering for Price Aggregators
Infatica offers a large pool of high-quality residential proxies. You can choose the pricing plan that fits your needs and budget, or ask us to come up with a tailored plan for you if required.
By using proxies and advanced scrapers, you will minimize the risk that your scraper gets detected. Therefore, the data gathering process will be fast and effective. Just don’t forget to set up the scraper so that it doesn’t send requests too frequently. Otherwise, even proxies won’t keep you from getting blocked.
Frequently Asked Questions
A bot could be programmed to perform engagement manipulation, where bots are used to like, comment, or follow users en masse in order to artificially inflate engagement metrics. Or a bot could be created to spread false information and rumors in an attempt to manipulate public opinion.
One common type of anti-bot CAPTCHA is a test that requires the user to enter text that is displayed in an audio clip. The user must listen to the audio clip and then enter the text into a text box. This type of CAPTCHA is designed to prevent automated programs from completing the test by automatically typing the text from the audio clip.
Bots are computer programs that automatically carry out tasks on social media platforms. They can be used for a variety of purposes, from promoting a brand to interacting with customers. bots can either be standalone programs or integrated into existing software platforms. Some popular examples of bots include Twitter bots and Facebook Messenger bots.
No, CAPTCHA does not stop all bots. In fact, many bots are designed to bypass CAPTCHAs. However, CAPTCHA can be an effective tool for stopping some bots. For example, a bot that relies on being able to click a certain button on a webpage will be stopped by a CAPTCHA that requires human input to click the button.
It's a cryptocurrency trading bot. These are computer programs that use pre-defined rules to automatically trade cryptocurrencies on exchanges. For example, a bot could be programmed to buy BTC when the price drops below $6000 and sell it when it reaches $8000. Bots can also be programmed to execute more complex strategies, such as arbitrage (taking advantage of price differences between exchanges). Trading bots are widely used by traders to take emotion out of trading decisions and execute trades faster and more efficiently. Many institutional investors also use bots to trade large orders without moving the market.




{kind=link}
{kind=link}