Denis Kryukov is using his data journalism skills to document how liberal arts and technology intertwine and change our society
Tallinn, Estonia
Proxy
Gaming with Proxies: Reduce Lag, Avoid Bans & Play Securely
Want to lower ping, avoid bans, or protect against DDoS attacks? Discover the best proxies for gaming and how to set them up on any device.
Infatica updates
Connecting with Industry Leaders: Infatica at Affiliate World & ABC MeetMarket Dubai
Meet Infatica at two of Dubai’s premier marketing events: Affiliate World Conference and ABC MeetMarket!
Proxies and business
How Infatica Overcame Google’s 2025 JavaScript Update for Seamless Web Scraping
Discover how Infatica keeps Google scrapers operational in light of Google’s 2025 JavaScript update – by rendering JavaScript and using advanced anti-blocking strategies.
Proxy
Proxies and Firewalls: A Comprehensive Comparison
Let’s understand proxies and firewalls more in depth: Compare their features, advantages, and use cases to decide which is right for your network needs.
Proxies and business
Unlock Higher-Paying Remote Tasks Using Residential Proxies
Residential proxies enable access to diverse, high-paying tasks on remote work platforms. See how they can help users from various regions increase online income!
Proxies and business
Infatica at Affiliate World Asia 2024: Join Us in Bangkok!
Join Infatica at Affiliate World Asia 2024 in Bangkok! Visit booth B64 on December 4–5 to meet our experts and explore our proxy solutions.
Access TamilYogi Anywhere: Best Tools and Tips for Unblocking
Frustrated with TamilYogi blocks? This guide explains how to use proxies, VPNs, and other tools to bypass restrictions for uninterrupted streaming.
Proxies and business
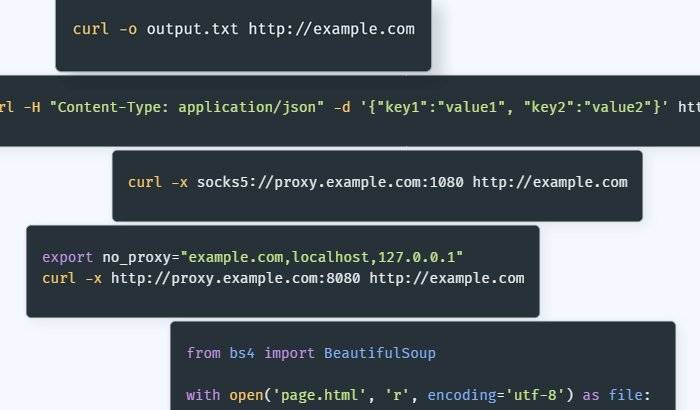
How to Use curl With Proxy
This guide shows how to use curl proxy to access geo-restricted websites. Learn different ways of setting up curl with a proxy and some examples of common commands.
Building a Real Estate Data Scraper: Code, Proxies, and Best Practices
Looking to scrape real estate data? Our guide covers everything from the basics to advanced techniques, including using proxies and processing data for actionable insights.
Proxy
Best Proxies For Scrapy
Learn how to use proxies with Scrapy to optimize your web scraping projects. Discover the best types of proxies, how to set them up, and why they're essential for data collection.
Integrations
How To Configure Ghost Browser Proxy Settings
Learn how to configure Ghost proxy settings for enhanced privacy and productivity in Ghost Browser in this comprehensive guide with step-by-step instructions and tips.
Proxy
Introducing Infatica's Dedicated ISP Proxies: Secure and Scalable
We're excited to announce the launch of our new dedicated ISP proxies. Learn about its pros and order them today!
Get In Touch
Have a question about Infatica? Get in touch with our experts to learn how we can help.