Main > Blog > Price Scraping: What it is, how it is done and who needs it
Price Scraping: What it is, how it is done and who needs it
Learn the essentials of price scraping, its benefits, legalities, and challenges. Discover advanced tools like proxies and Infatica Scraper API for effective data extraction.
Price scraping holds great potential for many e-commerce companies – but how to perform it efficiently? In this article, you'll discover the fundamentals of price scraping, including how it works and its benefits for businesses. We'll explore the legal and ethical considerations, the challenges involved, and effective methods to protect against scraping. Additionally, you'll learn about practical use cases, such as competitor price monitoring and dynamic pricing strategies, and how price scraping tools like proxies and Infatica Scraper API can enhance your data collection efforts.
What is price scraping?
The price scraping definition is pretty simple: It’s a method used to extract pricing information from various online sources, typically e-commerce websites. It involves automated scripts, known as web scrapers, which send requests to web pages, retrieve the HTML content, and parse it to extract the relevant data. This data can then be stored in databases for further analysis and comparison. Price scraping allows businesses to monitor competitors' prices, track market trends, and adjust their pricing strategies accordingly. It is an essential tool for e-commerce, allowing companies to stay competitive by keeping up-to-date with the latest pricing information.
The process of price scraping involves several stages: identifying the target web pages, sending HTTP requests to these pages, and parsing the HTML content to locate the price elements. Libraries such as BeautifulSoup or Scrapy in Python are commonly used to handle these tasks. Once the prices are extracted, they are cleaned and normalized before being stored in a database. Extracted data can then be analyzed to identify trends, generate reports, or feed into pricing algorithms. While price scraping offers significant competitive advantages, it also requires careful consideration of legal and ethical implications, ensuring compliance with website terms of service and avoiding excessive server load on the target website.
Is price scraping legal?
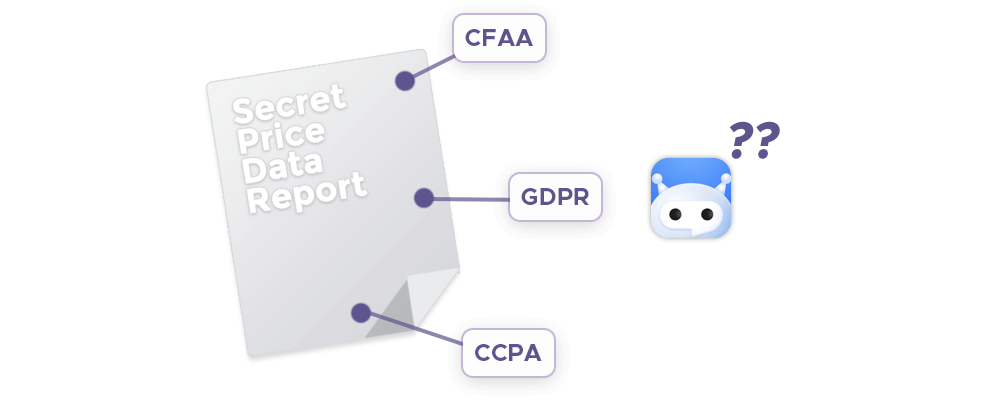
The legality of price scraping resides in a gray area and often depends on the jurisdiction and specific circumstances of each case. Generally, price scraping is legal, but issues arise when it involves terms and conditions violations, copyright infringement, or unauthorized access to proprietary information. In the United States, for instance, the Computer Fraud and Abuse Act (CFAA) has been used to prosecute cases where scraping is deemed unauthorized access, particularly if it involves circumventing technological barriers like CAPTCHAs or login requirements. Court rulings have varied, with some decisions favoring data scraping as a legitimate business practice while others have sided with website owners, emphasizing their right to control access to their data.
In Europe, the General Data Protection Regulation (GDPR) introduces additional complexities, particularly concerning the collection and processing of personal data. Companies engaging in price scraping must ensure they are compliant with GDPR provisions, such as obtaining consent when necessary and ensuring data subjects' rights are protected. Ethical considerations also play a crucial role; responsible scraping practices include respecting the website's robots.txt file, which specifies the site's scraping policies, and avoiding actions that could harm the website's functionality or performance. Ultimately, the legal landscape for price scraping is evolving, and businesses must stay informed about relevant laws and court rulings to navigate this complex terrain responsibly.
Who uses price scraping?
Let’s take Amazon price scraping as an example – here are some types of businesses that would particularly benefit from it:
E-commerce retailers can use price scraping to monitor competitor prices on Amazon and adjust their own pricing strategies accordingly. By staying competitive with their pricing, they can attract more customers and increase sales. Additionally, retailers can identify pricing trends and seasonal fluctuations, enabling them to optimize inventory levels and promotional strategies. This data-driven approach helps e-commerce businesses remain agile and responsive to market changes.
Manufacturers and brands can benefit from Amazon price scraping by gaining insights into how their products are being priced and positioned by various sellers. This information can help them enforce Minimum Advertised Price (MAP) policies and ensure brand consistency across different sellers. By monitoring unauthorized price drops or discrepancies, manufacturers can take corrective actions to maintain their brand’s value and reputation. Additionally, understanding competitors’ pricing strategies can inform product development and marketing efforts.
Market research firms can leverage price scraping to gather extensive data on product pricing, availability, and consumer behavior on Amazon. This data can be used to generate detailed market analysis reports, helping their clients understand market dynamics and make informed business decisions. By analyzing price trends, customer reviews, and sales rankings, market research firms can provide valuable insights into market demand, competitive landscapes, and potential growth strategies.
Price comparison websites can use Amazon price scraping to provide accurate and up-to-date pricing information to their users. By aggregating prices from Amazon and other e-commerce platforms, these websites help consumers find better deals and make informed purchasing decisions. Accurate and comprehensive price data enhances the reliability and attractiveness of price comparison websites, driving more traffic and increasing user engagement.
Investment firms can use price scraping on Amazon to monitor market trends, consumer preferences, and the performance of specific brands or products. This information can be valuable for making investment decisions, assessing the health of retail companies, and identifying emerging market opportunities. By analyzing prices alongside sales volumes and customer feedback, investment firms can gain a deeper understanding of market dynamics and potential risks.
How Price Scraping Works
A price scraping pipeline involves several stages to collect, process, and store pricing data from various online sources. Here’s a breakdown of how such a pipeline typically works:
Requirements and setup: Determine what pricing data is needed, from which websites, and how frequently it should be collected. Select programming languages (e.g., Python), libraries (e.g., BeautifulSoup, Scrapy), and frameworks that will be used for scraping and data processing.
Web scraping: Identify the URLs of the web pages that need to be scraped. Parse the HTML content using libraries such as BeautifulSoup or lxml to extract the relevant pricing data.
Data storage: Use a database (e.g., MySQL, MongoDB) to store the scraped data.
Data processing: Aggregate data if needed, such as averaging prices from different sources – and validate the data to ensure accuracy and remove any anomalies or errors.
Data analysis and reporting: Finally, perform data analysis to identify trends, patterns, or insights from the collected pricing data. Create visualizations (e.g., charts, graphs) to present the analysis results.
What kind of data can you scrape?
There are multiple facets of scraped data – let’s take a closer look at them:
Brand Name
Scraping data for brand names on Amazon allows businesses to monitor the presence and performance of competitor brands. This information is crucial for brand management and enforcement of brand guidelines. Companies can track how their brand is being represented, identify unauthorized sellers, and ensure that branding is consistent across different listings. Understanding the visibility and popularity of various brands helps businesses refine their marketing strategies and enhance customer loyalty.
Attributes
Scraping product attributes such as specifications, features, and dimensions enables businesses to compare their offerings with competitors in detail. This information helps in product development, allowing companies to identify gaps in the market and innovate to meet customer needs. Detailed knowledge of product features also assists in creating more effective and targeted marketing campaigns, highlighting features that differentiate their products from others. Additionally, it aids in optimizing product listings to improve search rankings and conversion rates on Amazon.
Product Name
Scraping product names allows businesses to analyze naming conventions and trends used by competitors. Product name matching helps in optimizing product titles to include relevant keywords that enhance search engine visibility and attract more customers. By understanding how competitors name their products, businesses can also identify opportunities to stand out or align with popular naming trends. Effective product naming can significantly impact click-through rates and overall sales performance on Amazon.
Price & Promotion
Scraping pricing data and discounts is essential for competitive pricing strategies. By continuously monitoring prices, businesses can adjust their own pricing to stay competitive, attract price-sensitive customers, and maximize profits. Understanding discount patterns and promotional activities of competitors enables businesses to time their own discounts and sales events more effectively. This data-driven approach helps in optimizing pricing strategies to boost sales volumes and customer acquisition.
Availability
Scraping product availability data helps businesses understand stock levels and supply chain efficiency of their own products and those of competitors. This information is vital for inventory management, ensuring that popular products are always in stock and avoiding lost sales due to stockouts. Monitoring competitors' availability can also provide strategic insights; for instance, a competitor's frequent stockouts may present an opportunity to capture their market share. Effective inventory management, informed by availability data, helps in maintaining customer satisfaction and loyalty.
Uses of Price Scraping for eCommerce
Price data that you get from, say, Amazon can be used in several interesting scenarios. Let’s take a closer look at them:
Competitor price monitoring
Price scraping for competitor price monitoring allows e-commerce businesses to keep a close watch on the pricing strategies of their competitors. When businesses harvest data on competitors’ prices, they can make informed decisions to adjust their own prices to remain competitive. This real-time insight helps in identifying underpriced or overpriced products, understanding market positioning, and reacting swiftly to competitors' promotional activities. Effective competitor price monitoring helps maintain market relevance and can lead to increased sales and market share.
Price optimization
Price scraping facilitates price optimization by providing detailed data on how different pricing points affect sales and customer behavior. Businesses can analyze this data to identify the optimal price that maximizes both sales volume and profit margins. By understanding the relationship between price changes and demand, companies can implement strategic pricing adjustments that enhance profitability while staying competitive. This data-driven approach ensures that the best price is neither too high to deter customers nor too low to erode profits.
Identifying pricing trends
Scraping prices regularly allows businesses to identify and analyze pricing trends over time. By examining historical pricing data, companies can detect patterns such as seasonal fluctuations, market cycles, and emerging pricing strategies. This insight helps in forecasting future price movements and planning inventory and marketing strategies accordingly. Understanding pricing trends also aids in anticipating competitor actions and market shifts, enabling proactive and strategic decision-making.
Dynamic pricing strategies
Price scraping is crucial for implementing dynamic pricing strategies, where prices are adjusted in real-time based on market conditions, demand, and competitor pricing. This approach maximizes overall revenue by responding to changes in the market swiftly. For instance, during high demand periods, prices can be increased, while in low demand periods, discounts can be offered to boost sales. Dynamic pricing relies heavily on accurate and up-to-date data from price scraping to ensure that pricing adjustments are timely and effective, leading to better sales performance and customer satisfaction.
The benefits of price comparison scraping
With enough effort, you can scrape prices and make this data actionable – and get these benefits of price scraping:
Competitive pricing: You can monitor competitors' prices in real-time. By staying informed about the pricing of competitor strategies, companies can adjust their own prices to remain competitive, attract customers, and avoid losing market share.
Price optimization: With access to comprehensive pricing data, businesses can perform price optimization to determine the ideal price points that maximize sales and profit margins. This ensures that prices are set at levels that attract customers while maintaining profitability.
Inventory management: By monitoring product availability and pricing trends, businesses can better manage their inventory levels. Understanding which products are in high demand and which are frequently out of stock helps in maintaining optimal inventory levels, reducing stockouts, and avoiding overstock situations.
Business intelligence: Price scraping contributes to broader pricing intelligence efforts by providing critical data that can be integrated with other business metrics. This holistic view enables more informed decision-making across various aspects of the business, from pricing and marketing to inventory and sales.
Cost savings: Automating the process of price monitoring through scraping reduces the need for manual data collection, saving time and resources. This efficiency allows businesses to allocate their resources more effectively and focus on strategic activities rather than tedious data gathering.
Price scraping challenges
However, there are also important price scraping challenges that we need to keep in mind:
IP blocking and rate limiting: Websites often implement IP blocking and rate limiting to prevent automated scraping. These measures can disrupt scraping activities, requiring the use of proxy servers and techniques to mimic human behavior. Overcoming these defenses while respecting the website’s policies can be challenging and resource-intensive.
Frequent website changes: Websites frequently update their layouts and structures, which can break the scraping scripts. Maintaining and updating scraping scripts to adapt to these changes requires continuous monitoring and adjustments, leading to additional development and maintenance efforts.
Data quality and accuracy: Ensuring the accuracy and quality of the scraped data can be challenging. Inconsistent HTML structures, dynamic content, and incomplete data can result in erroneous or missing information. Implementing robust data validation and cleaning processes is essential to maintain data reliability.
Scalability: Scaling the scraping process to handle a large number of websites and data points efficiently can be complex. It requires robust infrastructure, efficient algorithms, and resource management to ensure that the scraping tasks are completed in a timely manner without overwhelming the system.
Handling CAPTCHAs and JavaScript: Many websites use Captchas and JavaScript to protect against automated scraping. Handling these mechanisms requires advanced techniques such as using OCR for Captchas or headless browsers like Puppeteer to execute JavaScript. These solutions add complexity and computational overhead to the scraping process.
Complexity of dynamic content: Scraping dynamic content generated by JavaScript, such as AJAX requests and infinite scrolling, adds complexity to the scraping process. Capturing this content accurately often requires sophisticated techniques and price scraping software capable of rendering and interacting with web pages as a human user would.
Is it possible to secure your website against price scraping?
Websites employ various methods to protect themselves against price scraping, aiming to maintain control over their data and prevent unauthorized access. One of the most common techniques is IP blocking and rate limiting. Competing sites track the frequency and pattern of requests coming from different IP addresses – and if a particular IP address makes too many requests within a short period, it can be flagged and blocked due to suspicious activity. Rate limiting involves setting a threshold for the number of requests that can be made within a certain timeframe, thereby reducing the likelihood of scraping activities. Websites can also use geoblocking to restrict access from certain regions or countries, making it harder for price scrapers to access the content from outside allowed locations.
Another defense mechanism is the use of CAPTCHAs, which require users to complete a challenge that is easy for humans but difficult for automated scripts, such as identifying objects in images or solving simple puzzles. This step ensures that the requester is a human rather than a bot. Advanced versions of CAPTCHAs can dynamically increase the difficulty based on the detected behavior of the requester, making it even more challenging for automated systems to bypass. Additionally, some websites use JavaScript and AJAX to load content dynamically, making it harder for traditional scrapers that rely on static HTML to extract data.
Websites also protect themselves through bot detection and behavioral analysis. They use machine learning algorithms to analyze traffic patterns and detect anomalies that suggest bot-like behavior. Characteristics such as the speed of navigation, mouse movements, and interaction patterns can be monitored to identify and block bad bots. Honeypot traps are another method where invisible fields or links are embedded within the web page. Human users typically do not interact with these elements, but more advanced bots might, leading to their detection and blocking. Lastly, websites enforce Terms of Service agreements that explicitly prohibit scraping activities. Legal measures can be taken against entities that violate these terms, serving as a deterrent to unauthorized scraping. Combining these methods creates a multi-layered defense system that significantly complicates the task of scraping while protecting the integrity and overall security of the website’s data.
Tools and technologies
Last but not least, let’s explore various tools that make price scraping much easier:
Proxies
Proxies enable scraper bots to circumvent various anti-scraping measures and scrape data efficiently. By masking the scraper's original IP address, proxies help avoid IP blocking and rate limiting imposed by websites. Here’s how different types of proxies can be useful for price scraping:
Residential proxies use IP addresses assigned by Internet Service Providers (ISPs) to homeowners. These proxies are perceived as legitimate users by websites because they appear to come from regular residential locations. They are highly effective at avoiding detection and blocking, making them ideal for scraping websites with stringent anti-scraping measures. For price scrapers, residential rotating proxies are generally the best pick.
Mobile proxies utilize IP addresses provided by mobile carriers. These proxies rotate through a pool of IPs as users connect to different cell towers. Mobile proxies are even more trustworthy in the eyes of websites due to the variability and volume of mobile IP addresses. They are beneficial for scraping high-security websites that frequently change their detection mechanisms.
Datacenter proxies originate from data centers and not ISPs. They offer high speed and availability but are more easily detected and blocked by sophisticated websites because they can be identified as non-residential IPs. They are suitable for scraping less protected websites or when speed is a higher priority than anonymity.
Rotating proxies automatically change the IP address used for each request or after a set period. This rotation helps distribute the requests across many IPs, reducing the risk of detection and blocking. Rotating proxies can be either residential or datacenter-based, combining the benefits of both types by offering anonymity and speed.
Web scraper
Infatica Scraper API simplifies the process of price scrapers by providing a powerful solution that integrates proxy management and data extraction capabilities. It offers several advantages:
High anonymity and reliability: Infatica uses a vast network of residential and mobile proxies, ensuring high success rates and minimizing the risk of being blocked.
Automatic IP rotation: The API handles IP rotation seamlessly, distributing requests across a large pool of IP addresses to avoid detection and rate limiting.
User-friendly interface: The API is designed to be easy to use, allowing users to focus on data extraction without worrying about managing proxies.
Compliance and security: Infatica adheres to legal and ethical standards, providing a secure and compliant scraping environment.
Frequently Asked Questions
It involves using automated price scraping tools to gather valuable information from competitors' websites. It helps businesses monitor market trends, adjust their own pricing strategies, and stay competitive in the marketplace.
Automating this involves using web scraping tools or APIs that can regularly fetch and extract pricing data from target websites. This automation ensures timely updates and requires fewer manual price scraping attempts in monitoring competitors' prices.
If a site blocks bots, it can prevent further data collection. For more efficient bot management, use rotating proxies to vary IP addresses, mimic human interactions by adding delays between requests, respect robots.txt rules, and monitor scraping volumes to stay within acceptable limits.
An example of price scraping is a retailer using automated scripts to extract the entire product catalog from e-commerce websites like Amazon or Walmart. This data helps them analyze market trends and adjust pricing strategies to retain the competitive edge.
No, price scraping is used by businesses of all sizes. Small to medium-sized enterprises also employ scraping to monitor competitors, optimize pricing, and gather market intelligence to improve their competitive position in the market.
Jovana is a freelance writer who likes to focus on the practical side of different technologies: Her stories answer both the "How does it work?" and "Why is it important for me?" questions.
You can also learn more about:
Web scraping
Introducing Infatica Data Platform: Web Data Collection Without Code
Infatica Data Platform helps teams collect structured web data from URLs, keywords, and prompts without writing code or managing proxies.
Proxies and business
Ethically Sourced vs. Unethically Sourced Proxies
Ethically sourced proxies come from users who consented; unethically sourced ones from hijacked devices. Here’s the difference, and how to tell them apart.
Proxies and business
The NetNut Takedown, Explained
Google and the FBI disrupted NetNut, a 2-million-device residential proxy network. Here’s what happened, and what it means if you buy residential proxies.
Get In Touch
Have a question about Infatica? Get in touch with our experts to learn how we can help.

















{kind=link}
{kind=link}