






Article content


Vlad Khrinenko
14 min read
It takes time, resources, and a bit of luck to unlock the untapped potential of web scraping and turn it into a lucrative business – but it just got a bit easier with our in-depth guide! This article will walk you through every step: You’ll discover essential programming languages, the most powerful tools like Scrapy and Beautiful Soup, and learn how to overcome technical challenges such as CAPTCHA and IP blocking. Ready to monetize your skills and stand out in a competitive industry? Read on!
Understanding Web Scraping
Web scraping is the automated process of extracting data from websites. Unlike manually copying information, web scraping uses bots or scripts to gather large amounts of data quickly and efficiently. This data can include anything from product prices, reviews, and user comments to entire website contents.
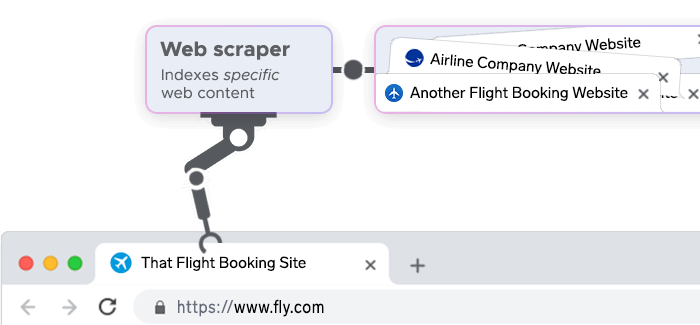
At its core, web scraping involves three key steps:
- Accessing the website: The scraper navigates to a webpage, similar to how you would use a web browser.
- Extracting data: The scraper identifies and collects specific pieces of information from the page, such as text, images, or links.
- Storing data: The collected data is then stored in a structured format, such as a spreadsheet or database, for further analysis or use.
Benefits of Web Scraping
Despite the challenges, web scraping offers numerous benefits, particularly for businesses and researchers looking to leverage large datasets. Here are some advantages:
- Efficiency: Web scraping can automate the collection of vast amounts of data, saving significant time and effort compared to manual data gathering.
- Scalability: Scrapers can be designed to handle increasing volumes of data as your needs grow, making them highly scalable solutions.
- Data-driven decisions: The data collected through web scraping can provide valuable insights, allowing businesses to make informed, data-driven decisions.
- Competitive advantage: By accessing real-time data, businesses can stay ahead of the competition by adapting quickly to market changes and trends.
Types of Data You Can Scrape
The data you can collect through web scraping is diverse and can be applied in various industries. Here are some examples:
- Product information: Prices, descriptions, availability, and customer reviews from e-commerce sites.
- Market research: Trends, competitor analysis, and consumer behavior data.
- Social media data: Posts, comments, likes, and follower counts from platforms like Twitter or Instagram.
- Real estate listings: Property details, prices, and locations from real estate websites.
- Job listings: Job titles, descriptions, company names, and application links from job boards.
Ways to Make Money with Web Scraping
Web scraping is a versatile skill that can be monetized in various ways, from freelance services to building entire businesses around the data you collect. Let’s explore the different avenues for generating income through web scraping, providing detailed examples, strategies, and tips for success.
Freelance services

One of the most accessible ways to make money with web scraping is by offering your services as a freelancer. Many businesses and individuals need data but lack the technical skills to collect it themselves. This creates a demand for web scraping experts who can deliver customized data solutions.
Upwork: Known for its wide range of professional services, Upwork is a great platform to find long-term clients or complex projects that require advanced web scraping skills. Create a detailed profile that highlights your expertise, showcases past projects, and includes client testimonials.
Fiverr: Fiverr allows freelancers to offer services starting at $5, though more complex tasks can be priced much higher. It’s ideal for smaller, one-off projects or for clients looking for quick turnaround times.
Freelancer: Similar to Upwork, Freelancer is another platform where you can bid on projects related to web scraping. It's competitive, but the diversity of projects can help you find work that matches your skills.
As a freelance web scraper, you can take on a variety of projects, such as:
Market research: Companies often need to collect data on competitors, industry trends, or consumer behavior. Web scraping can automate this process, allowing clients to make data-driven decisions.
Lead generation: Many businesses rely on scraped data to generate leads. By extracting contact information, such as emails and phone numbers from directories or social media platforms, you can help clients build their customer base.
Price monitoring: E-commerce businesses need to monitor competitors’ prices to stay competitive. You can scrape pricing data from various websites and deliver it in a format that clients can easily analyze.
Product data extraction: Retailers may need product details from suppliers' websites, including descriptions, specifications, and images. Web scraping can automate the extraction of this data, streamlining the process for clients.
Building and Selling Databases

Another lucrative way to monetize web scraping is by building and selling databases. This involves scraping data from multiple sources, cleaning and organizing it, and then selling it as a product to businesses or individuals who need it. To successfully sell databases, you need to identify industries that rely heavily on data. Some of the most common markets include:
Real estate: Real estate professionals need access to property listings, price trends, and neighborhood statistics. You can scrape data from real estate websites and create comprehensive databases that agents can use to identify opportunities and trends.
E-commerce: Online retailers and marketplaces require up-to-date information on products, prices, and reviews. A well-maintained database of this information can be highly valuable to businesses looking to optimize their inventory and pricing strategies.
Job market: HR departments and recruitment agencies need detailed information about job listings, company profiles, and candidate qualifications. By scraping job boards and professional networking sites, you can create databases that streamline the recruitment process.
There are several ways to monetize the databases you create:
One-time sales: Sell the database as a one-time purchase. This model is straightforward and appeals to clients who need data for a specific project or a short-term need.
Subscription-based access: Offer access to your database on a subscription basis. Clients pay a recurring fee to access the data, which you update regularly. This model provides a steady stream of income and encourages long-term client relationships.
API access: Instead of selling the entire database, provide access to it through an API (Application Programming Interface). Clients can query your database in real-time, paying per request or based on usage. This model is scalable and can accommodate clients with varying data needs.
Affiliate Marketing and Price Comparison Websites
Web scraping can also be used to create affiliate marketing websites or price comparison platforms. These sites attract visitors by providing valuable information and monetize through affiliate commissions or advertising.
Price comparison websites aggregate data from various retailers, allowing consumers to compare prices on products or services. By scraping product information, prices, and reviews, you can create a site that helps users find the best deals.
Selecting a niche: Focus on a specific market, such as electronics, fashion, or travel. Specializing in a niche can help you build a loyal audience and rank higher in search engine results.
Affiliate partnerships: Sign up for affiliate programs with retailers or affiliate networks like Amazon Associates, ShareASale, or CJ Affiliate. When users click through your links and make a purchase, you earn a commission.
SEO and content: Invest in search engine optimization (SEO) to drive organic traffic to your site. Regularly update your site with fresh content, such as product reviews, buying guides, or industry news, to engage visitors and improve your rankings.
Monetization strategies:
- Affiliate marketing: Earn commissions by promoting products or services through affiliate links. The more targeted your content, the higher the likelihood of conversions.
- Advertising: Place ads on your website through Google AdSense or direct partnerships with brands. As your traffic grows, so does your potential ad revenue.
- Sponsored content: Partner with brands to create sponsored posts or reviews. These partnerships can be lucrative, especially if you have a large and engaged audience.
Reselling Scraped Data to Companies

Another profitable avenue is to scrape data that businesses need but don’t have the resources to collect themselves. This approach requires a deep understanding of the industries you’re targeting and the specific data needs of potential clients.
Start by identifying industries where data is crucial for decision-making. Examples include:
- E-commerce: Online retailers need competitive pricing data, product availability, and customer sentiment analysis to make informed decisions.
- Real estate: Agencies and investors require property data, market trends, and demographic information to assess opportunities.
- Finance: Hedge funds, banks, and financial analysts rely on up-to-the-minute data on stocks, commodities, and economic indicators to inform their strategies.
When approaching potential clients, it’s essential to articulate the value of your data. Explain how your scraped data can solve specific problems, save time, or reduce costs. For instance:
Enhanced market intelligence: By providing comprehensive and up-to-date market data, you can help businesses stay ahead of competitors.
Operational efficiency: Data that automates routine tasks, such as price monitoring or lead generation, can free up resources for more strategic activities.
Risk management: Financial institutions, for example, can use your data to identify and mitigate risks, such as market volatility or credit exposure.
Pricing Your Services
Pricing strategies can vary depending on the value and uniqueness of the data you provide:
- Per project: Charge a flat fee for a specific data scraping project. This approach works well for one-off data needs.
- Subscription model: Offer ongoing access to regularly updated data for a monthly or annual fee. This model is ideal for clients who need continuous data feeds.
- Data licensing: License your data to multiple clients, allowing them to use it under specific conditions. This approach can maximize your revenue by selling the same data to different clients.
Technical Skills Required
To successfully monetize web scraping, you need a solid foundation in programming, data handling, and the use of various tools and frameworks. Let’s take a closer look at the programming languages you should master, the tools and frameworks that streamline the web scraping process, and the techniques for data cleaning and analysis.
Python
Python is the most popular language for web scraping due to its simplicity, readability, and the vast array of libraries that support web scraping tasks. Its syntax is beginner-friendly, making it accessible to those new to programming, while its powerful libraries make it indispensable for more advanced users.
Python Web Crawlers : Extensive Overview of Crawling Software | Infatica
Over the years, Python community has produced a plethora of great tools for web crawling and web scraping. In this article, we’ll explore these tools and analyze their most optimal usage scenarios.
 Denis Kryukov
Denis Kryukov
JavaScript
JavaScript is essential for scraping dynamic websites that rely heavily on client-side rendering with JavaScript frameworks like React, Angular, or Vue.js. Traditional scraping methods often struggle with these sites because the content is rendered after the initial HTML load, making it invisible to the scraper unless the JavaScript is executed.
Scrape Static and Dynamic Pages with JavaScript and Node.js | Infatica
Learn how to build a web scraper on Node.js with JavaScript in this step-by-step guide. You’ll discover how to perform scraping with Node.js and Puppeteer.
Jovana Gojkovic
Scrapy
Scrapy is a Python framework designed for large-scale web scraping projects. It’s highly efficient and can manage multiple requests simultaneously, making it ideal for scraping large websites. Scrapy comes with built-in functionalities for handling cookies, sessions, and user-agent strings, which can help you avoid getting blocked by websites.
Efficient Web Scraping Using Scrapy: Strategies and Best Practices
Let’s learn how to effectively use Scrapy for web scraping with this comprehensive guide – and explore techniques, handle challenges, and troubleshoot common issues to build efficient scrapers.
Pavlo Zinkovski
Spiders: In Scrapy, a spider is a class that defines how to follow links and extract data from web pages. You can create spiders that crawl multiple pages, scrape data, and save it in formats like JSON, CSV, or databases.
Middleware: Scrapy allows you to use middleware to customize the request and response processing. This can include setting proxies, handling redirects, or managing throttling to avoid overloading the server.
Beautiful Soup
Beautiful Soup is particularly useful for small-scale scraping tasks where you need to extract data from static websites. It works well with the requests library, allowing you to fetch and parse HTML or XML content easily.
Navigating the parse tree: Beautiful Soup’s strength lies in its ability to navigate the parse tree it creates from the HTML. You can easily search for tags, filter content, and retrieve text based on attributes like classes or IDs.
Data extraction: Whether you need to extract data from tables, lists, or specific HTML elements, Beautiful Soup provides a simple and intuitive API to get the job done.
Selenium
Selenium is a browser automation tool that’s often used in web scraping to handle websites that require JavaScript execution. Unlike Scrapy or Beautiful Soup, which work directly with HTML content, Selenium automates a real web browser, allowing you to interact with web pages as if you were a human user.
Automated browsing: Selenium allows you to open a browser, navigate to a website, interact with elements (like clicking buttons or filling out forms), and scrape the content that appears as a result. It’s particularly useful for scraping data from complex or dynamic websites.
Headless browsing: For faster and more efficient scraping, Selenium can be run in headless mode, which means it operates without opening a visible browser window. This can speed up the scraping process and reduce resource consumption.
Integration with Python and JavaScript: Selenium can be easily integrated with both Python and JavaScript, allowing you to leverage your programming skills across different scraping tasks.
Puppeteer
Puppeteer is a powerful tool for web scraping in environments where JavaScript execution is necessary. It’s especially useful for scraping single-page applications (SPAs) and websites that heavily rely on AJAX requests.
Introduction to Puppeteer: Automating Data Collection
Puppeteer is a powerful Node.js library for automation in Chromium-based browsers — let’s take a closer look at how it works and how to set it up for web scraping.
Denis Kryukov
Headless Chrome: Puppeteer runs a headless version of Chrome, allowing you to automate tasks without a graphical user interface. This makes it highly efficient for large-scale scraping projects.
Advanced Interactions: Puppeteer allows for complex interactions with web pages, including taking screenshots, generating PDFs, and even simulating user inputs like mouse clicks and keyboard strokes.
Pandas
Pandas is a powerful Python library for data manipulation and analysis. It’s widely used in web scraping projects for handling large datasets, cleaning data, and performing exploratory data analysis (EDA).
DataFrames: Pandas introduces the DataFrame, a two-dimensional, size-mutable, and potentially heterogeneous tabular data structure. DataFrames are ideal for storing and manipulating structured data scraped from websites.
Data Cleaning: Pandas provides various functions to handle missing data, remove duplicates, and convert data types. For example, the dropna() function can be used to remove missing values, while fillna() can replace them with a specified value.
Data Transformation: Pandas makes it easy to transform data by applying functions across rows or columns, merging datasets, and reshaping data. This is essential when preparing your data for analysis or exporting it to other formats.
Challenges and How to Overcome Them
Web scraping offers vast opportunities, but it also comes with its share of challenges. These obstacles can range from technical hurdles to industry competition, all of which need to be addressed effectively to build a successful and sustainable web scraping business.
CAPTCHA
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a widely used anti-scraping measure that presents challenges designed to distinguish between human users and bots. CAPTCHAs can take various forms, including distorted text, image recognition, and more advanced puzzles. While bypassing CAPTCHA can be tricky, there are several methods to handle this challenge:
Manual CAPTCHA solving: For small-scale scraping projects, you can manually solve CAPTCHAs. However, this method is impractical for large-scale scraping due to its time-consuming nature.
CAPTCHA solving services: Third-party services like 2Captcha, Anti-Captcha, and Death by CAPTCHA provide solutions where humans solve CAPTCHAs in real-time, allowing your scraper to continue functioning without interruption.
How to Avoid CAPTCHAS: Strategies for CAPTCHA-Free Web Scraping | Infatica
Learn how to avoid CAPTCHA and bypass CAPTCHA challenges in web scraping with effective strategies such as rotating proxies, mimicking human behavior, and rendering JavaScript.
Jovana Gojkovic
Machine learning models: Advanced users may develop machine learning models to solve CAPTCHAs automatically. However, this approach requires significant expertise and may not work for all types of CAPTCHAs.
IP Blocking
Websites often monitor the IP addresses of incoming requests to detect and block suspicious behavior, such as multiple requests from the same IP in a short period. If your IP is flagged, you may be blocked from accessing the website. There are several strategies to avoid IP blocking:
Rotating proxies: Use a pool of rotating proxies to distribute requests across multiple IP addresses, reducing the likelihood of any single IP being flagged. Proxy services like Infatica offer reliable options for IP rotation.
How To Crawl A Website Without Getting Blocked: A Guide You Need | Infatica
Scraping without getting blocked can be challenging, but several methods — including proxies, User-Agents, and more — can help you collet data with less blocks.
Pavlo Zinkovski
User-Agent spoofing: Websites often block requests that appear to come from non-human browsers. By rotating User-Agent strings, you can mimic different browsers and devices, making your requests appear more human-like.
Rate limiting: Implement rate limiting in your scraping script to mimic human browsing behavior. By slowing down your requests and introducing random delays between them, you can reduce the likelihood of being detected and blocked.
Honeypot Traps
Some websites employ honeypot traps—hidden elements on a page that real users cannot see but bots might inadvertently interact with. If your scraper interacts with these elements, the website can flag your activity as automated.
Honeypots: What Are They? Avoiding Them in Data Gathering
Honeypots may pose a serious threat to your data collection capabilities: They can detect web crawlers and block them. In this article, we’re exploring how they work and how to avoid them.
Pavlo Zinkovski
To avoid honeypot traps, ensure that your scraper only interacts with visible elements on the page. You can achieve this by checking the visibility of elements before interacting with them and ignoring any hidden fields or links.
Frequently Asked Questions
Web scraping is legal in many cases, but it depends on the website’s terms of service, the type of data being scraped, and local laws. Always ensure you’re compliant with relevant regulations and obtain permission if required. Avoid scraping sensitive, copyrighted, or personal data without proper authorization.
Python is the most popular language for web scraping due to its simplicity and a wide range of libraries like Beautiful Soup, Scrapy, and Requests. However, JavaScript, particularly with Node.js and Puppeteer, is essential for scraping dynamic websites that rely heavily on JavaScript.
To avoid getting blocked, use rotating proxies to change IP addresses, implement rate limiting to mimic human behavior, and rotate User-Agent strings. Additionally, consider using headless browsers like Selenium or Puppeteer for more sophisticated interactions with dynamic websites.
Pandas is a powerful Python library widely used for data cleaning and preprocessing. It allows you to handle missing values, remove duplicates, and normalize data formats. Pandas, combined with other libraries like NumPy and SciPy, provides a comprehensive toolkit for managing large datasets.
CAPTCHAs can be managed by using CAPTCHA-solving services like 2Captcha or Anti-Captcha. For more advanced users, machine learning models can be developed to solve CAPTCHAs automatically. However, always consider the ethical implications of bypassing CAPTCHAs and ensure compliance with legal guidelines.



{kind=link}
{kind=link}