






Article content


Jovana Gojkovic
12 min read
On many popular websites, CAPTCHAs serve as a vital defense mechanism against automated bots – but they can also pose significant challenges for web scraping endeavors. In this article, we explore various strategies to circumvent CAPTCHAs during web scraping, including mimicking human behavior, adjusting scraping speed, and leveraging advanced techniques like rendering JavaScript. After reading this guide, you will gain insights into effectively navigating CAPTCHA challenges and how to avoid CAPTCHA tests during your web scraping efforts.
Why CAPTCHAs Affect Business Research

CAPTCHAs (Completely Automated Public Turing tests to tell Computers and Humans Apart) are widely used on websites to stop bots from abusing services. While they serve a crucial role in enhancing online security, CAPTCHA challenges can significantly impact business research in several ways:
Data Collection Challenges
Many businesses rely on automated tools for analyzing data for competitive research, or consumer behavior insights. CAPTCHA blocking can limit these tools, limiting the ability to gather necessary data. Additionally, researchers often use web scraping techniques to extract large volumes of data from various online sources – and CAPTCHAs make it difficult to scrape data efficiently, leading to incomplete datasets or increased manual effort.
Increased Operational Costs
When data collection tools are hindered by CAPTCHAs, businesses may need to resort to manual data collection, which is time-consuming and labor-intensive – and this increases operational costs. Furthermore, some businesses might opt to use CAPTCHA solving services or tools, which adds to the costs and potentially introduces reliability and ethical issues.
Data Integrity and Quality
Interestingly enough, one of web scraping challenges is the introduction biases in the collected data: For instance, if only certain segments of users are able to bypass a CAPTCHA, the resulting data may not be fully representative of the target population. In other scenarios, inability to bypass CAPTCHAs can lead to incomplete data sets, which can compromise the validity and reliability of research findings.
Limitations on Automated Interaction
Last but not least, businesses that interact with web services through APIs might face limitations if CAPTCHAs are implemented, which can restrict the flow of information and affect integrations crucial for research purposes.
Types of CAPTCHAs
All CAPTCHA types leverage different human cognitive and motor abilities to prevent even the most modern bots from accessing certain functions or data. Here are the most popular CAPTCHA implementations, which you may see on search engines, social media platforms, e-commerce websites, etc.:
Image CAPTCHA
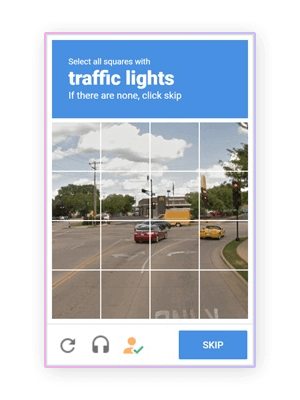
- How it works: Users are presented with a set of images and asked to identify or select specific items or objects (e.g., Google's reCAPTCHA: "Select all images with traffic lights").
- Purpose: Exploits human ability to recognize and interpret visual information contained within the CAPTCHA image, which is challenging for bots.
Audio CAPTCHA
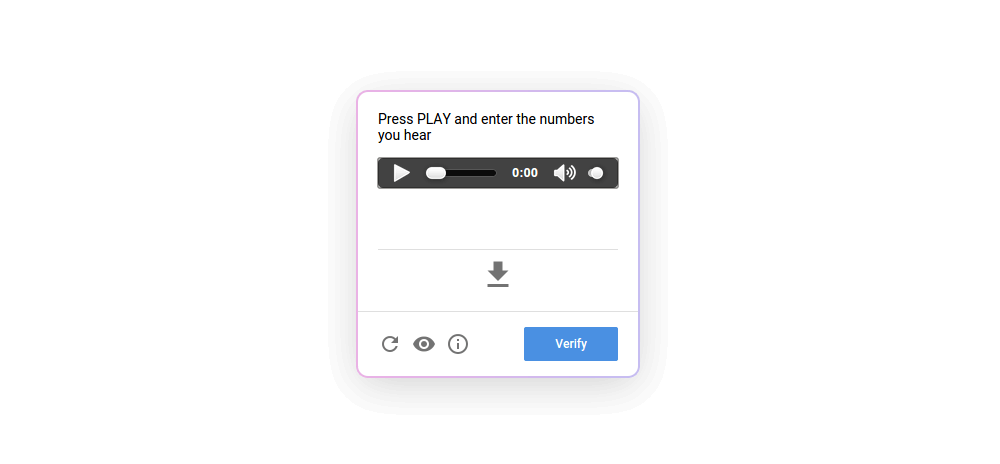
- How it works: Users listen to a distorted audio clip and must type the words or numbers they hear.
- Purpose: Provides an alternative for visually impaired users. It leverages human auditory processing capabilities, which are difficult for bots to mimic.
Text CAPTCHA

- How it works: Users are asked to type a sequence of distorted or obscured letters and numbers displayed in an image.
- Purpose: Relies on the human ability to decipher text CAPTCHAs, which bots typically struggle with.
Math CAPTCHA
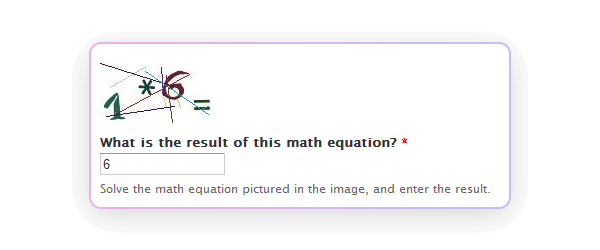
- How it works: Users solve CAPTCHAs in form of simple arithmetic problems (e.g., "What is 3 + 4?") and enter the answer.
- Purpose: Simple for humans but requires logical processing that many bots may not be equipped to handle.
Interactive CAPTCHA
- How it works: Users perform a simple interactive task, such as dragging and dropping objects, rotating items to the correct orientation, or clicking in specific sequences.
- Purpose: Utilizes human motor skills and understanding of interactive tasks, which are challenging for bots to replicate accurately.
Checkbox CAPTCHA
- How it works: Users check a box labeled "I'm not a robot." This may be accompanied by additional behavioral analysis, such as tracking mouse movements or monitoring the time taken to complete the action.
- Purpose: Appears simple but often involves behind-the-scenes analysis of user behavior to differentiate humans from bots.
How to Avoid a CAPTCHA
There are multiple methods to identify CAPTCHA blocking and avoid error codes associated with it – let’s take a closer look at some of them:
Use rotating proxies
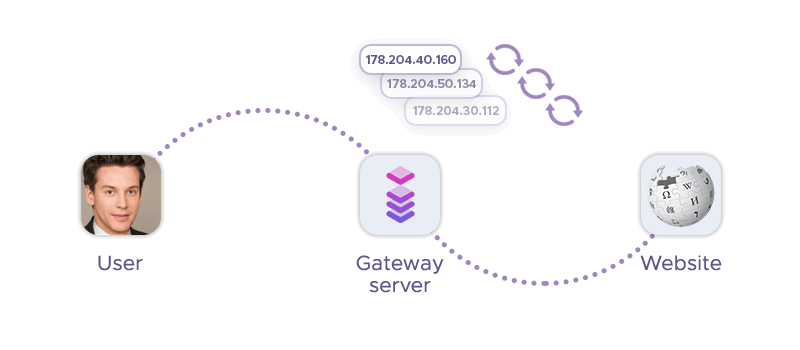
Rotating proxies periodically change the IP address used for multiple requests: This means that each request to the target site can come from a new IP address. By mimicking requests from numerous different users, rotating proxies reduce the likelihood of triggering anti-bot measures like CAPTCHAs, which often activate when multiple connection requests come from a single IP address in a short period.
Both datacenter proxies and residential proxies can also help with avoiding rate limits: Website owners often impose limits on the number of requests an IP address can make within a given timeframe. Rotating proxies help distribute the load across many IP addresses – and this distribution helps stay under the radar of rate limiting thresholds, reducing the chances of CAPTCHAs being triggered due to high request volumes.
Finally, rotating proxies can be configured to use IP addresses from different geographical locations. As some websites use geo-targeting or geo-fencing to detect unusual traffic patterns, using IPs from diverse locations can make the traffic appear more natural and less likely to be flagged as suspicious.
Adjusting scraping speed
Websites often monitor the frequency and pattern of incoming requests to identify potential bots. If the requests come in too quickly or in a highly regular pattern, it raises red flags that can trigger CAPTCHAs – and adjusting the scraping speed can mitigate these problems:
Slowing down the rate of requests makes the scraping activity resemble human browsing, which typically involves pauses and irregular intervals between actions. This reduces the chances of detection by CAPTCHA systems designed to spot rapid, repetitive actions.
Rapid, high-volume requests can spike server load, triggering security measures including CAPTCHA tests. With a lower scraping speed, you can maintain a lower profile, avoiding such triggers.
Randomizing request patterns

Anti-bot systems identifying patterns that deviate from typical human interactions. When requests are uniform and predictable, it signals bot activity: CAPTCHA systems use algorithms to spot consistent, rapid, or repetitive request patterns – however, by varying the timing, sequence, and frequency of requests, scrapers can evade these algorithms, reducing the likelihood of triggering the “alarm”.
Additionally, uniform request patterns create anomalies that stand out in server logs, prompting security mechanisms – and randomization blends scraping activity into normal traffic patterns, lowering the risk of detection.
Moreover, randomized patterns help distribute requests more evenly, avoiding bursts of activity that might attract attention. This stealth approach helps maintain access to the target website without triggering defensive measures.
Rotate User-Agents
User-agents are strings sent in HTTP headers that identify the browser, operating system, and device type making the request. Websites use these strings to tailor content and optimize pages – but also to detect and block bots. Rotating them can be beneficial because:
Each request appears to come from a different browser or device. This diversity prevents the server from recognizing repetitive patterns that are characteristic of bots, reducing the chances of triggering CAPTCHAs.
Some CAPTCHA systems use fingerprinting techniques to identify and block requests that consistently come from the same user-agent. Changing user-agents frequently helps avoid the CAPTCHA’s detection, making the scraping activity appear as if it's coming from multiple genuine users.
Human traffic naturally comes from a variety of browsers and devices. By rotating user-agents, scrapers can better mimic this natural diversity, blending in with regular traffic, which will help to avoid reCAPTCHA.
User Agents For Web Scraping: How to Scrap Effectively with Python | Infatica
User agents may seem insignificant, but that’s not the case: As their name suggests, they contain valuable data — and they can also make web scraping easier.
 Sharon Bennett
Sharon Bennett
Use Real Headers
Similarly, request headers contain various pieces of client information, such as the browser type, acceptable content types, and referrer URL. Authentic headers help in blending scraping requests with regular traffic, reducing the likelihood of detection.
This is because real headers, including accurate user-agent strings, accept-language, and referrer information, make scraping requests appear genuine. This authenticity can help the requests avoid getting flagged as automated – and prevent CAPTCHAs.
Human users' browsers naturally send a variety of headers. By replicating these headers accurately, scrapers can better mimic normal browsing behavior, making it harder for CAPTCHA verification systems to identify the requests as bot-generated.
Websites often analyze header information to detect bot indicators. Using real, dynamic headers helps in avoiding such detections, as the requests align more closely with expected patterns.
Last but not least, some systems (e.g. Google reCAPTCHA) trigger based on missing or incorrect headers. Ensuring that all headers are correctly formatted and reflective of real user activity can bypass CAPTCHA checks.
Implement Headless Browsers

Headless browsers can help avoid CAPTCHAs during web scraping by allowing for automated browsing without displaying a graphical user interface (GUI). Since CAPTCHAs often rely on visual challenges, headless browsers bypass this obstacle by executing scripts and rendering web pages in headless mode. This approach enables scraping scripts to interact with websites just like a regular browser, reducing the likelihood of triggering CAPTCHAs.
Tools like Selenium and Puppeteer navigate websites and interact with elements programmatically, without rendering the content visibly. This invisible interaction reduces the chances of CAPTCHA detection, as there is no user interface for CAPTCHA systems to interact with.
Despite lacking a graphical interface, headless browsers can simulate human-like browsing behavior by executing JavaScript, clicking buttons, filling forms, and scrolling through the web page. This emulation helps avoid triggering CAPTCHAs by making the scraping activity appear more natural.
Finally, a headless browser provides powerful browser automation capabilities: It enables automated scraping at scale, allowing for the extraction of large volumes of data without human intervention. This efficiency reduces the likelihood of human-like patterns that could trigger CAPTCHAs.
What is Headless Browser? The Essentials You Need to Know | Infatica
Dive into headless browsers, the key to speed and resource efficiency in web processes. Learn to optimize your testing and development tasks effortlessly.
Sharon Bennett
Mimic Human Behavior

Mimicking human behavior during web scraping helps avoid a CAPTCHA by making the scraping activity appear indistinguishable from genuine user interactions. CAPTCHA systems are designed to track navigation and detect abnormal or automated behavior, such as rapid, repetitive requests. By replicating human-like actions such as mouse movements across the X and Y coordinates, hover, clicks, and random actions, scrapers can avoid patterns that give their true nature away.
To mimic behavior of a real user, the bot must also use real headers, rotate user-agents, and adjust scraping speed to create a natural browsing experience. This approach reduces the likelihood of triggering CAPTCHAs, allowing for more efficient and uninterrupted data extraction.
Check for honeypots
Honeypots are essentially invisible CAPTCHAs: They are hidden form fields that are visible only to bots, not to human users. When a bot fills out these fields, it reveals itself as automated, triggering honeypot CAPTCHAs or IP bans. Scrapers can detect honeypots by inspecting the HTML code or by analyzing CSS properties, such as visibility or display.
Honeypots are often hidden from human users using properties like CSS visibility (i.e. visibility:hidden). By checking for these properties, scrapers can avoid filling out fields intended for bots.
By skipping form fields marked as honeypots, scrapers can prevent triggering a CAPTCHA challenge. Moreover, honeypot detection helps scrapers navigate websites more efficiently by avoiding unnecessary interactions with traps, reducing the likelihood of disruptions or bans.
Honeypots: What Are They? Avoiding Them in Data Gathering
Honeypots may pose a serious threat to your data collection capabilities: They can detect web crawlers and block them. In this article, we’re exploring how they work and how to avoid them.
Olga Myhajlovska
Avoid direct links

Avoiding direct links can help avoid CAPTCHAs during web scraping by circumventing detection mechanisms that target specific URLs or endpoints frequently accessed by bots. CAPTCHA systems often monitor patterns of access to high-value or sensitive pages, triggering challenges when they detect suspicious users.
Instead of accessing websites directly, scrapers can dynamically generate URLs using parameters or variables. This prevents the CAPTCHA test from identifying predictable patterns associated with bot activity.
Websites sometimes use referrer information to track user navigation. Scrapers can spoof or manipulate referrer headers to make requests appear as if they originated from legitimate sources, reducing the likelihood of detection.
Additionally, scrapers can simulate human-like browsing behavior by navigating through a website randomly rather than following predetermined paths. This randomness helps with avoiding CAPTCHAs by making the scraping activity less predictable.
Certain pages or endpoints on a website may be more heavily monitored for bot activity. By avoiding direct links to these hotspots, scrapers can reduce the risk of encountering CAPTCHA or other defensive measures.
Render JavaScript

JavaScript rendering can help avoid CAPTCHAs during web scraping by allowing scrapers to interact with websites dynamically and execute client-side code. Many modern websites rely heavily on JavaScript for content rendering and user interaction. Without JavaScript rendering, scrapers may miss important data. By rendering JavaScript, scrapers can access and extract data from dynamically generated content, making their activity appear more like genuine user interaction.
JavaScript-rendered websites often load content dynamically, making it inaccessible to scrapers that do not execute JavaScript. By rendering JavaScript, scrapers can access and extract web data from these dynamic elements.
Some CAPTCHA systems rely on JavaScript to validate user responses. By rendering JavaScript, scrapers can handle CAPTCHA triggers programmatically, effectively bypassing CAPTCHA challenges without human intervention.
Finally, JavaScript rendering ensures that scrapers capture the most up-to-date and accurate data by accessing content that may be generated dynamically based on user interactions or other variables.
How to avoid a CAPTCHA with Infatica?

One of our key products is the residential proxy network, which provides access to a vast pool of residential IP addresses. These proxies rotate periodically, distributing web requests across multiple IPs, making it difficult for websites to detect and flag the activity as automated. By using residential IPs, which are associated with real devices and locations, Infatica ensures that web scraping activities appear more natural and less likely to trigger complex CAPTCHAs or other security measures.
Infatica’s data collection suite, Scraper API, utilizes our residential proxy servers, too. Try it if you don’t want to manage the web scraper yourself.
Conclusion
Overcoming CAPTCHAs is a crucial aspect of successful web scraping. Mimicking human behavior, avoiding direct links, and rendering JavaScript can help scrapers evade detection mechanisms and ensure uninterrupted access to valuable data. With these techniques, you are equipped to tackle CAPTCHA challenges head-on and optimize your web scraping pipeline for greater efficiency and effectiveness.
Frequently Asked Questions
CAPTCHA, or Completely Automated Public Turing test to tell Computers and Humans Apart, is a security measure used by websites to differentiate between genuine users and automated programs. It typically involves tasks like typing distorted text or selecting images to prove human identity.
Websites use CAPTCHAs to prevent malicious bots from abusing their services, such as spamming forms, creating fake accounts, or conducting malicious activities. On the other hand, a search engine (e.g. Google) would use CAPTCHAs to prevent their data from getting scraped.
CAPTCHAs pose challenges for web scrapers by hindering automated data collection processes. They can disrupt scraping tools, increase operational costs, and compromise data quality. Overcoming CAPTCHAs requires employing strategies like mimicking human behavior or using CAPTCHA solving services.
A residential rotating proxy provides IP addresses assigned to residential devices, and they rotate periodically to mimic genuine user behavior. They aid in CAPTCHA avoidance during web scraping by distributing requests across multiple IP addresses, making it harder for websites to detect and block bot activity.
Yes, using multiple CAPTCHA avoidance techniques simultaneously, such as rotating proxies, mimicking human behavior, and adjusting scraping speed, can enhance effectiveness. However, there are risks, including increased complexity, potential detection by sophisticated CAPTCHA systems.




{kind=link}
{kind=link}