Main > Blog > How To Crawl A Website Without Getting Blocked
How To Crawl A Website Without Getting Blocked
Scraping without getting blocked can be challenging, but several methods — including proxies, User-Agents, and more — can help you collet data with less blocks.
Getting blocked is a major problem for many companies: If you want to collect data for business and marketing strategies, SEO, performance tracking, or something else, you need to learn more about scraping without getting blocked. Dive into the dynamic world of web scraping with our comprehensive guide! Learn to navigate the complexities of data extraction while staying within legal confines. This article will equip you with the knowledge of how to crawl a website without getting blocked, optimize efficiency, and ethically harvest the data you need.
1. Check Permissions Before Scraping
Robots.txt and Terms of Service are two important factors to consider before scraping a website:
Robots.txt is a file used by websites to tell search engine web crawlers which pages and files they should not access. This is used mainly to avoid overloading your site with requests; it is not a mechanism for keeping a web page out of Google.
Terms of Service are the rules and policies that a website imposes on its users, which may affect how you can access and use its data. Some websites may prohibit or restrict scraping altogether, or require you to obtain permission or follow certain copyright guidelines before doing so.
Therefore, for scraping without getting blocked, it is essential to check these documents before scraping a website, and respect their boundaries and permissions. You should also consider using rate limiting techniques to control the number of requests per the same IP and add delays between requests, as this can help you avoid overloading the website or triggering anti-scraping measures. Rate limiting can help you enforce granular access control, protect against credential stuffing and account takeover attacks, limit the number of operations performed by individual clients, and protect REST APIs from resource exhaustion or abuse.
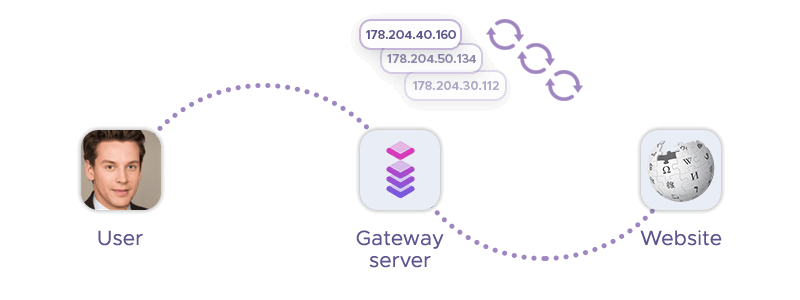
2. Use Rotating Proxies for Web Scraping Anonymity
Rotating proxies automatically change the source IP address with each new request or after a predefined number of requests. This automated IP rotation ability allows rotating proxy servers to prevent getting blocked while scaling data extraction capabilities. IP blocks are often triggered by websites to avoid overloading their site with requests from the same IP address, or to protect their data from unauthorized access.
Infatica is a global provider of proxy services, offering residential, mobile, and datacenter proxies for businesses and individuals across different regions. These services allow users to rotate IP addresses – and they are used for a variety of purposes, including scraping without getting blocked, data mining, and improving online privacy. Infatica's residential proxy pool helps companies to improve their products, research target audiences, test apps and websites, prevent cyberattacks, and much more.
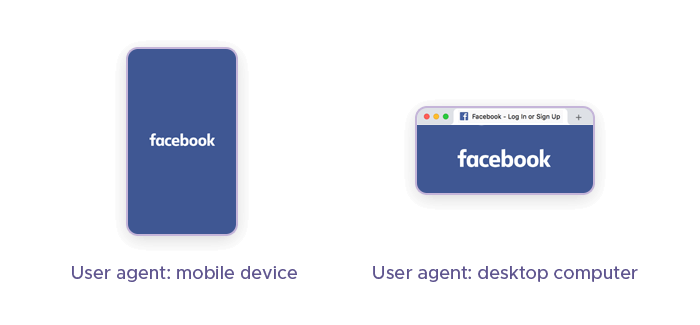
User agent strings are HTTP request headers that identify browsers, applications, or operating systems that connect to a server. They can help you mimic a real user and avoid detection mechanisms and getting blocked by websites that use anti-scraping techniques.
By changing your user agents, you can perform spoofing of different types of devices, real browsers, or screen sizes and customization of your scraping behavior. This can help you avoid getting blocked by websites that use robots.txt, terms of service, or referrer header to restrict or prohibit scraping.
It is recommended to change your user agent string regularly and use a combination of techniques, such as using a headless browser, proxy management, proxy rotation, or user-agent rotators, to enhance your stealthy web scraping. This can help you overcome the challenges of web scraping without getting blocked or blacklisted by websites.
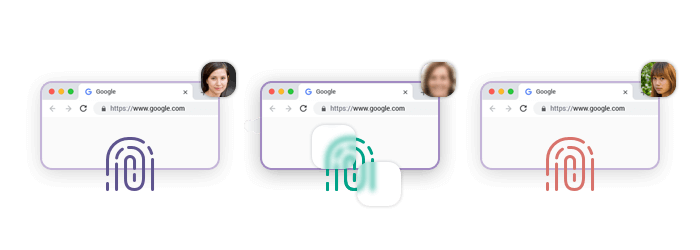
TCP/IP fingerprinting is a technique used to identify the operating system and other characteristics of a remote device by analyzing the data fields in TCP/IP packets. This method examines various parameters such as initial packet size, TTL (Time to Live), window size, and others to create a unique signature or fingerprint of the device.
Websites can use TCP/IP fingerprinting to detect irregular parameter patterns that may indicate user agent spoofing to conduct scraping without getting blocked. Even if a scraper uses a popular user agent string, the underlying TCP/IP stack characteristics of the device making the requests can still be analyzed and compared against known patterns. This helps websites identify and block scrapers or bots that are trying to disguise their true identity.
Regularly changing user agents can help evade some level of detection, but TCP/IP fingerprinting provides a deeper level of scrutiny that can reveal the true nature of the traffic, making it a powerful tool against scrapers who want to access a website without getting blocked.
5. Identify Traps and Honeypots
Hidden honeypot links are a security measure used by websites to detect web crawlers and deter unauthorized web scraping. These links are not visible to regular users browsing the site but can be detected by automated web scraping tools. When a scraper follows these hidden links, it reveals itself as a bot, which can lead to its IP address getting blocked or other countermeasures being taken by the website.
Moreover, interacting with honeypots can lead to legal issues. While honeypots themselves are not illegal, using them for public data gathering, even of malicious parties, may breach privacy laws. It's important to consider all applicable privacy laws and anti-hacking laws before employing honeypots.
Before crawling websites, it's advisable to check for invisible traps like honeypots. This can be done by having well-defined crawling rules, avoiding invisible links, and validating sitemaps and robots.txt contents. Using headless browsers to verify details can also help in identifying such traps. This precaution helps to ensure that you can keep scraping without getting blocked.
Regularly checking target sites for structural changes is another good practice: Websites often update their layout and elements. Such changes can break web scrapers that rely on specific patterns and locations to retrieve data. If the web scraper is not updated to adapt to these changes, it may fail in scraping without getting blocked or collecting data that is inaccurate.
Web scraping tools must be robust and flexible to handle site changes. Proactive change detection and adapting the scraping code accordingly can prevent disruptions in data collection and ensure the reliability of the scraped data. It's a best practice to design scrapers that can quickly adjust to layout updates or alert you to significant changes that require manual intervention.
By staying vigilant and updating your scrapers, you can maintain the efficiency and accuracy of your web scraping operations, avoiding potential data loss and continue scraping without getting blocked.
7. Mimick Human Behavior
Predictable bot navigation is often getting blocked: It can be detected through patterns that don't resemble typical human behavior. Websites might use static rules to detect bots, like sending HTTP headers in an unexpected order or navigating too quickly through pages. To appear more human and avoid detection:
Varied delays between requests: Introduce random pauses between actions to mimic the irregular pace of human browsing.
Randomness: Simulate human-like interactions by incorporating random mouse movements, clicks, and scrolling. This can help in evading simple bot detection mechanisms.
Using different user agents and headless browsers can also contribute to scraping without getting blocked. However, sophisticated detection systems may still identify bot activity through deeper analysis like TCP/IP fingerprinting, so it's important to use a combination of techniques for effective evasion.
8. Add JavaScript Rendering
JavaScript and its technologies like AJAX are essential for scraping without getting blocked: They enable asynchronous data retrieval and manipulation, allowing parts of a web page to update without a full page refresh. This results in a smoother user experience and reduced web server load, as only specific data is requested and loaded.
Regarding detection avoidance, JavaScript can help simulate human-like interactions, making automated scraping activities less detectable by anti-bot measures. It can dynamically load content, handle user interactions, and perform tasks that are crucial for modern websites.
Headless browsers are indeed useful for executing JavaScript, especially when scraping dynamic web pages. They can render JavaScript-powered web applications, providing a means to interact with web pages programmatically as if they were a real user. This capability is particularly important for scraping sites that rely heavily on JavaScript to render their content. Using headless browsers like Puppeteer, Selenium, or Playwright allows you to execute JavaScript and scrape websites that would otherwise be inaccessible with traditional HTTP requests.
9. Bypass CAPTCHAs
CAPTCHAs pose a significant challenge for web crawlers because they are designed to distinguish between human users and automated programs. CAPTCHAs often require the recognition of distorted text or images, tasks that are generally easy for humans but difficult for bots. This is because CAPTCHAs rely on a person's ability to recognize patterns and nuances that bots, which typically follow predetermined patterns or enter random characters, struggle with. Scrapers typically address CAPTCHAs by employing various techniques such as:
CAPTCHA-solving services: CAPTCHA services use human labor or advanced algorithms to solve CAPTCHAs presented during scraping data.
Machine learning and OCR (Optical Character Recognition): Some scrapers use these technologies to interpret the CAPTCHA images or text.
CAPTCHA farms: These are systems where humans solve CAPTCHAs in large numbers, often for a fee.
Anti-CAPTCHA libraries: These are software tools designed to bypass CAPTCHAs by automating the solving process.
10. Optimize Speed and Timing
Throttling traffic is a good practice in web scraping: It involves limiting the rate of successful requests to stay under the website's rate limits and avoid overloading the server. This can help prevent your scraper from being detected and blocked.
Avoiding peak times is also beneficial as it reduces the load on the target site's server and minimizes the chances of your scraping activities affecting the website's performance for regular users. Scraping during off-peak hours can lead to a smoother scraping experience and reduce the likelihood of getting blocked.
Both strategies are part of ethical scraping practices that respect the target site's resources and ensure a more reliable data collection process. Implementing delays to avoid too many requests and varying the timing can also contribute to a more human-like interaction pattern, further reducing the risk of getting blocked. Always ensure to follow the terms of service of the website without getting blocked.
11. Streamline Data Acquisition
Avoiding non-critical images and multimedia is recommended for bandwidth optimization and storage needs. This approach isn’t necessarily tied to getting blocked, but it helps in reducing the overall size of web pages, leading to faster loading times. It also conserves server resources and minimizes costs associated with data transfer and storage. Here are some strategies for optimizing images:
Compress images: Use tools to reduce file size without compromising quality.
Use appropriate formats: Choose the right image format (e.g., JPEG, PNG, WebP) for the content.
Lazy loading: Load images only when they are needed or visible on the user's screen.
Image sprites: Combine multiple images into one to reduce the number of server requests.
12. Avoid Geo-Blocking
Region blocking is a technique used by many websites to restrict access to their content if scraping requests originate from suspicious regions. This can interfere with web scraping efforts when trying to access region-specific content or when scraping from regions that are deemed suspicious and thus getting blocked.
Reliable proxies can solve this problem by masking the scraper's real IP address and providing an alternate IP address from a different geographic location. By routing web requests through various proxy locations, the scraper can appear to be accessing the website from those specific locations, thereby circumventing getting blocked and obtaining region-specific data. This level of anonymity and location masking is essential for conducting effective geo-targeted scraping, allowing scrapers to access content as if they were in a non-restricted region.
Headless browsers (e.g. Chrome headless) are web browsers without a graphical user interface, making them ideal for automated tasks like web scraping. They can help avoid getting blocked in several ways:
JavaScript rendering: They can render pages and execute JavaScript like a real web browser, which is crucial for scraping dynamic content that changes without a full page reload.
Mimic human behavior: By programmatically behaving like a human user, headless browsers can evade detection by most websites that block scrapers.
Modify User-Agent and browser fingerprint: They can alter their user-agent and browser fingerprint to avoid easy detection, appearing as different devices or browsers.
Using headless browsers, such as Puppeteer, Playwright, or Selenium, allows scrapers to interact with web pages more effectively, bypassing some basic anti-scraping protections and reducing the likelihood of getting blocked.
Scraping from the Google Cached version of a site can be a strategic choice for sites with infrequently changing data or static content. It can help avoid getting blocked because you're not forcing the website to block requests and trigger anti-scraping measures by accessing data heavy objects. However, it's important to note that scraping Google's cache still involves legal and ethical considerations, and you should ensure compliance with Google's terms of service.
Additionally, the cached version may not always be up-to-date, so it's crucial to verify the freshness of the extracted data. If the data's timeliness is not a critical factor, using the cached version can be an efficient way to access the information without putting extra load on the target site's server.
Remember to use this method responsibly and consider the potential implications on both the target site and the caching service provider. Always prioritize respecting the website's terms of use and legal restrictions when scraping content.
15. Use Referrers
Setting a referrer to Google or spoofing the same country as the target website can make scraping activities appear more like those of a real user and avoid getting blocked. This is because many users come to websites from search engines like Google, and having a local referrer can reduce the likelihood of raising suspicion.
Tools like SimilarWeb can provide insights into traffic sources, including referrer headers, which can help identify common referrers for a particular website without getting blocked. This information can be used for spoofing referrers when scraping to mimic typical user behavior.
16. Use Cookies
Reusing cookies after solving CAPTCHAs can sometimes allow continued website access without getting blocked or needing to redo CAPTCHAs. Websites often store cookies to remember that a user has passed a CAPTCHA challenge, recognizing them as a human on subsequent visits. By maintaining these cookies, a scraper can potentially avoid triggering CAPTCHAs again, at least for a certain period.
However, this method's effectiveness can vary depending on the website's security measures and how frequently they reset or expire their cookies. It's also important to use this technique ethically and in compliance with the website's terms of service. Always ensure that your web scraping project is conducted responsibly and within legal boundaries – and you’ll be able to access almost any website without getting blocked.
17. Maintain GDPR Rules
Following the General Data Protection Regulation (GDPR) is extremely important for any entity handling the data of EU citizens. GDPR sets stringent guidelines for data collection, processing, and storage to protect personal data and privacy rights. Compliance is crucial because violations can lead to severe consequences, including getting blocked, hefty fines that can reach into the tens of millions of euros, or even higher for more serious breaches.
Moreover, non-compliance with EU data laws can damage a company's reputation, lead to a loss of customer trust, and potentially result in bans from operating within the EU. The regulation also empowers individuals with greater control over their personal data, making it essential for organizations to adhere to GDPR to maintain consumer confidence and avoid legal penalties.
Conclusion
You've now traversed the landscape of web scraping, equipped with the tools and tactics to extract data seamlessly and ethically. With these newfound strategies, you're learned how to crawl a website without getting blocked, ensuring success in your data-driven endeavors. Keep scraping smartly and responsibly!
Frequently Asked Questions
Web scraping itself is not illegal, but it can be considered illegal if you scrape data without the permission of the website owners, acquire personal data without consent, or violate any terms of service or intellectual property rights. Web scraping is legal if you scrape data publicly available on the internet.
Some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data. Web scraping can also be influenced by the website's terms of use, which may contain clauses that restrict or prohibit scraping. Additionally, web scraping can be affected by legal actions against web scraping, such as the Computer Fraud and Abuse Act (CFAA) in the US, or the Digital Millennium Copyright Act (DMCA) in the EU.
There are several methods to check and bypass the blocking. One of the most effective methods is to use a virtual private network (VPN), which can hide your IP addresses and location and help you access websites that are getting blocked by filters or algorithms. You can also use tools like IsitBan or Blocked to check if your website or any other website is being blocked by filters or ISPs.
As Infatica's CTO & CEO, Pavlo shares the knowledge on the technical fundamentals of proxies.
You can also learn more about:
Infatica updates
Infatica at G Gate Conference 2025: Connect with Us in Tbilisi
Attending G Gate Conf 2025? Meet Infatica and connect with leaders in affiliate marketing across iGaming, Nutra, Crypto, Fintech, Whitehat & Sweepstakes at EXPO Georgia in Tbilisi.
Web scraping
Making API Calls in Python: Authentication, Errors, and Proxies
Want to build scalable, reliable API integrations in Python? This guide covers requests, headers, proxies, and error handling – with practical examples.
Proxies and business
Ping Explained: How Latency Affects Your Connection Speed
From gaming to scraping – see how ping affects performance and how proxies can help keep it low.
Get In Touch
Have a question about Infatica? Get in touch with our experts to learn how we can help.



























{kind=link}
{kind=link}