






Article content


Vlad Khrinenko
5 min read
The stock market has become even more popular as various platforms and apps arrived and made this approach to investments more accessible to everyone. Those interested in the stock market can find out the best time for selling and buying from different sources — from trends found on relevant platforms to guides and paid consultations from experts.
Generally, it’s enough to read the news and stay tuned with what’s going on with companies and markets you’re interested in and process this information to quite accurately predict which stocks to buy and when to sell ones you own.
However, although the formula sounds simple, investing is actually quite complex: You’d need to process a lot of information, let alone finding reputable sources and looking for necessary bits of info there. If you want to be really successful in investing in stocks, you need to have a complete and up-to-date understanding of what’s going on. Wouldn’t it be nice if someone gathered all the info for you and structured it to make it easy for you to consume quickly?
The good news is that there is “someone” who can do that for you — the data collection industry has created a plethora of tools that automate this process. Let's take a closer look at them.
What is data collection?
The name is quite self-explanatory — data gathering is the process of gathering data. In our case, we would gather it from the internet, so we could call this activity “web scraping”, too: We’re essentially scraping information from web pages. Actually, it’s not us gathering the data. A special program — a web scraper — will do this for us. All we need to do is to set up the scraper by telling it what kind of information to gather and from where.

Then, the scraper will head to target websites, go through all the information published there, and only pick up the bits we'd told it to bring. After that, the program will process gathered data and transform it into a format that would be understandable for us humans. So, the only thing we need to do now is to study the extracted information without consuming lots of unnecessary data and wasting time looking for the required info.
❔ Further reading: Web Crawling vs. Web Scraping: Understanding the Difference
What data to gather for planning your investments?
You could make a scraper fetch you:
- News about companies you’re interested in,
- Stock market trends,
- Expert opinions on stocks and business environment,
- Important world news that could impact the stock market,
- New investing opportunities,
- Changes in stock prices, and much more.
Besides letting you know the next move you need to take to make the most out of your investments, this kind of data can also help you improve the efficiency of your business: Essentially, the more information you have, the more chances you get to establish a successful company. But knowledge about what’s going on with other companies and events that could impact your market will help you plan better and predict things so that your business is always ready for anything.
Issues you can face during web scraping
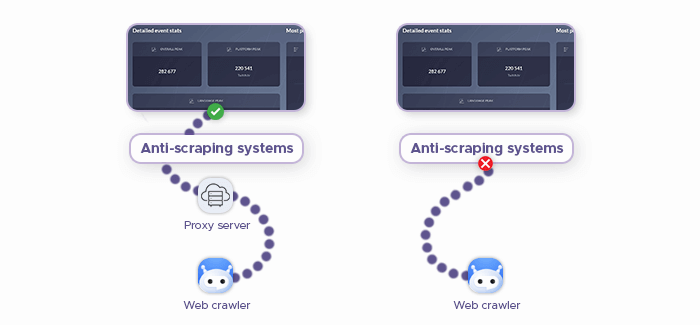
Data gathering sounds easy — just tell the scraper what data to gather and from where, and it will do the job. And it was that easy until malefactors started using this tool to steal intellectual property and gather data that wasn’t made publicly available. This forced website owners to take action and start protecting their content from theft.
Another issue, related to data gathering, is DDoS attacks: They’re performed with the help of bots, which malefactors use to send countless requests to the destination server until it gets overloaded by traffic and shuts down, making any website hosted on it go down, too. If a web scraper is set up incorrectly, its activity looks like a DDoS attack, triggering anti-DDoS mechanisms on the target website. As a result, this scraper gets banned and can’t gather info from the site.
Those are two reasons why data gathering can get complicated, but you can address these issues. First of all, you need residential proxies. Infatica offers high-quality residential proxies that will cover your IP address and mask it with an IP of an existing real device, making a destination server believe that the user of this device is accessing the website. With Infatica, you can assign a new proxy to each request your scraper sends to make its activity look like it’s many different users that are accessing a website.
❔ Further reading: Residential Proxies: A Complete Guide to Using Them Effectively
Another thing you should do is to make sure your scraper is sending a reasonable number of requests to a destination server. Sure, it feels like it will get the job done faster if you make the bot send 1000 requests per second. But then even the best proxies won’t save you — the server will begin panicking and might shut down or start denying access. There is no standard for the scraper’s speed. But if you see the latency of requested web pages increasing, it’s a sign to decrease the speed of your bot.
❔ Further reading: 9 Tips To Prevent Your Proxies from Getting Blocked
Finally, it’s smart to use libraries of headers to make requests from your scraper look more natural. Real users always have headers in their requests, so a headless request will be suspicious.
These are the most basic tips on successful data scraping — and if you dive into this topic, you’ll find many more ways to simplify the gathering of information for your investment needs. The more data you have before making a decision about your stocks, the more chances there are for this decision to bring satisfactory results. So add web scraping to your set of tools and let it simplify and increase your income from working with the stock market.
Frequently Asked Questions
A common method is to use public records, which can include information from financial institutions, the government, or other sources. Financial data can also be collected through market research, which involves observing and recording the buying and selling patterns of consumers. Another alternative is scraping the company's income statement and balance sheets.
Financial data can come in many different forms, but typically it includes information about the company's finances, such as income statements, balance sheets, and cash flow statements. This data can be used to assess a company's financial health and make investment decisions.
Financial news platforms (e.g. Bloomberg or Reuters) offer vast databases of financial data that you can access – often for a premium. The U.S. Bureau of Economic analysis can be another source, coupled with the "Historical Quotes" section on the NASDAQ website.
Generally, U.S. courts and various intellectual property regulations agree that web scraping is legal – but republishing and reselling scraped data isn't. Per the fair use doctrine, you need to transform this data in a meaningful way and generate new value for the user (e.g. create a price aggregator from scraped product prices.)





{kind=link}
{kind=link}