Main > Blog > Best Web Scraping Proxies: Everything You Need to Know
Best Web Scraping Proxies: Everything You Need to Know
Enhance your data collection capabilities with proxies for web scraping, designed for speed, reliability, and anonymity. Access any server globally without restrictions and gather data efficiently.
Proxies for web scraping are a powerful tool – dive into the comprehensive realm of web scraping with our detailed guide. Learn to harness the power of proxies to navigate servers with ease, ensuring your data collection is both stealthy and efficient. Elevate your scraping web scraping project with our insights.
What Is a Web Scraping Proxy?
A scraping proxy acts as an intermediary between your web scrapers and the websites you’re targeting. Here’s how proxy servers work on a basic level:
Request Routing: When your scraper sends a request to a website, instead of going directly from your computer to the website, it goes through the proxy server to hide the IP address.
IP Masking: The proxy server uses its own IP address to make the request to the website. This masks your actual IP address, which can help prevent the website from detecting and blocking your scraper.
Data Retrieval: Once the proxy server receives the data from the website, it forwards it back to your scraper.
IP Rotation: To further avoid detection, many scrapers use multiple proxies and rotate them. This makes the traffic appear as if it’s coming from different users.
Why Use a Proxy for Web Scraping?
Using proxies in web scraping is a strategic way to efficiently gather data while minimizing the risk of detection and blocking. Here's how scraping proxies can be beneficial in the scenarios you mentioned:
Overcoming IP blocking and bans
IP Rotation: Proxies can rotate IP addresses, making it difficult for websites to track and block the scraper based on IP.
Diverse IP Pool: Using a large pool of proxies from different subnets helps to avoid IP blocking, as requests appear to come from multiple, unrelated sources.
Ensuring anonymity and privacy
Masking Identity: Proxies hide your actual IP address, which is tied to your location and identity, thus maintaining your anonymity, avoiding geographical restrictions, and helping to protect privacy.
Encryption: Some proxy services offer encrypted connections, adding an extra layer of privacy and security to your scraping activities.
Distributing requests to avoid rate limits
Load Balancing: By distributing requests across multiple proxies, you can spread the load and avoid triggering rate limits that are based on the number of requests from a single IP – and improve performance of your scraper.
Throttling Control: Proxies can help manage request timing, ensuring that the scraper doesn't exceed the number of allowed requests in a given time frame.
Factors to Consider When Choosing Proxies
Each factor plays a role in determining the overall effectiveness of your web scraping efforts. It's important to assess your specific needs and choose proxy providers that offer the best combination of these elements. Here's how these factors influence the choice of a scraping web scraping proxy:
Speed and reliability
Speed is crucial for efficient scraping, especially when dealing with large volumes of web data or real-time data. Reliability ensures that the proxy for web scraping is consistently available and doesn't drop requests, which could disrupt the scraping process.
IP rotation capabilities
IP rotation helps avoid detection by regularly changing the IP address that makes requests, simulating different users. Proxies with advanced rotation features can better mimic human behavior, reducing the chance of being blocked or banned.
Geographical location of IP addresses
Certain content may only be available in specific regions. Proxies with geo-targeting capabilities can access websites with such geo-restricted data. Moreover, proxies closer to the target server can have faster response times, improving overall scraping efficiency.
Protocol compatibility
Proxies must support the protocols used by your scraper (e.g., HTTP, HTTPS, or SOCKS proxies) to ensure seamless integration and communication. Some advanced features, like header modification or request rerouting, may require specific protocol support.
Cost considerations
The cost of proxies can vary widely, so it's important to balance the budget with the required features. Consider the long-term value, such as the benefits of fewer blocks and bans, which can save resources and time in the long run.
Types of Proxies for Web Scraping
Different proxies are designed for different tasks – let’s take a closer at major proxy types for a better understanding of their strengths and weaknesses:
Datacenter proxies are intermediary services that provide you with an alternative IP address from a data center's pool of IPs. These proxies are housed in data centers and are not affiliated with Internet Service Providers (ISPs). They are known for their speed and reliability, making them suitable for tasks that require high-volume, anonymous internet requests. This proxy also has two subtypes:
Datacenter shared proxies: These are used by multiple clients at the same time. They are more cost-effective and can provide a degree of anonymity. However, they may offer slower speeds due to shared bandwidth and have a higher risk of being blacklisted by websites.
Datacenter dedicated proxies: Also known as private proxies, these are exclusively used by one client. They offer better performance, security, and stability but are more expensive compared to shared proxies.
Datacenter proxies can be very effective for market research and competitor analysis. They allow for fast and reliable data collection, which is crucial in tasks like e-commerce scraping. By using different IP addresses, they help in avoiding detection and bans from websites that may restrict access based on IP recognition.
Pros:
Cost-Effective: Datacenter proxies are generally less expensive than other types of proxies.
High Speed: They offer fast connection speeds, which is beneficial for scraping large volumes of data.
Scalability: They can handle a large number of web scraping requests simultaneously, making them suitable for big data projects.
Cons:
Less Legitimate: They may be considered less legitimate than residential or mobile proxies, which can lead to a higher chance of being blocked.
Fixed Location: The IPs usually come from data centers in specific locations, which might not be ideal for all geo-targeting needs.
Risk of Detection: Since datacenter IPs are known to be used for proxy services, some websites have measures to detect and block them.
Residential proxies
Residential proxies are intermediary servers that use ISP-registered IPs, not those of a data center. Each residential proxy address is associated with a physical location, and real residential devices, making them appear as regular internet users. They are particularly useful for tasks that require a high degree of authenticity and non-detectability, such as web scraping and accessing geo-restricted content.
A residential proxy can help access geo-restricted content and ad verification. Masking your real IP address, they hide your actual IP address, making it appear as if you are browsing from a different location. Mimicking local users by using IPs assigned to real residential locations, they can bypass geo-blocks and access content as if you were a local user.
Pros:
Authenticity: They are less likely to be detected as proxies because they come from a real internet service provider.
Location Targeting: They support precise location targeting, which is essential for tasks like market research or content localization.
Large IP Pools: They offer a wide range of IPs, making it easier to scale operations and manage multiple connections.
Cons:
Cost: Residential IPs are generally more expensive than other types of proxies.
Variable Performance: The speed and reliability can vary depending on the real user’s network conditions.
Mobile proxies are intermediary servers that route internet traffic through mobile devices connected to cellular networks, such as 3G, 4G, or 5G. They assign a mobile IP address to your device, replacing your original address, which helps in masking your real IP and maintaining anonymity online.
Mobile IPs are particularly useful on social media platforms. Firstly, they allow the management of multiple users without triggering platform restrictions or bans due to IP detection. Additionally, they mask the source of mobile testing and automated activities, such as commenting and liking, making them appear as actions from different users. Finally, they enable access to region-specific content and interactions, which is crucial for localized marketing strategies.
Pros:
High Legitimacy: Mobile proxies are less likely to be blocked because they use IP addresses from real mobile devices, which websites recognize as legitimate users.
Dynamic IP Rotation: They frequently change IP addresses, which helps in reducing the risk of detection and IP blocking.
Access to Mobile-Specific Content: They can access content and services tailored for mobile users, providing a more authentic browsing experience.
Cons:
Cost: Mobile proxies are generally more expensive than other types of proxies due to the costs associated with mobile data plans.
Limited Availability: The availability of mobile proxies can be restricted based on the number of mobile devices in the proxy network.
Variable Performance: The performance can fluctuate depending on the signal strength and network conditions of the private mobile devices used.
Rotating proxies
Rotating proxies are dynamic proxy servers that automatically change the IP address with each new request or after a predefined interval. This feature helps to prevent IP blocks and allows for large-scale data extraction, offering enhanced anonymity and efficiency compared to static proxies.
Rotating proxies can bypass geo-restrictions by ensuring each request appears to come from a different location, thus avoiding detection and blocking. Additionally, they can help with accessing content as if the user is in a different geographical location, which is useful for services that limit access based on user location.
Pros:
Increased Privacy: They provide a higher level of anonymity and security.
Reduced IP Blocking: Getting a brand new IP address reduces the risk of being blocked by target websites.
Scalability: Suitable for tasks that require handling a large number of requests, such as web scraping.
Cons:
Cost: They can be more expensive than other types of proxies.
Proxy management: There may be issues with maintaining sessions due to frequent IP changes.
Here's a more detailed look at the best practices for managing a proxy pool:
Identify Bans
Detection: Implement automated detection systems that can identify when a proxy has been banned or blocked by a website.
Response: Once a ban is detected, the proxy should be temporarily disabled or permanently removed from the pool.
Analysis: Analyze the reasons behind the bans to adjust your scraping strategy and avoid future occurrences.
Retry Errors
Automated Retries: Use a system that automatically retries a failed request with a different proxy.
Error Logging: Keep logs of errors to identify patterns that might indicate a problem with specific proxies or target websites.
Adaptive Strategy: Adjust the number of retries and the selection of proxies based on success rates.
Control Proxies
Allocation: Develop a system for allocating proxies to tasks based on their performance, reliability, and suitability for the target site.
Monitoring: Continuously monitor the health and performance of proxies to ensure they are functioning as expected.
Rotation: Rotate proxies based on a schedule or after a set number of requests to prevent detection.
Adding Delays
Human-like Interaction: Introduce random delays between requests to simulate human browsing patterns.
Rate Limit Adherence: Configure delays to adhere to the rate limits of the target website, reducing the risk of triggering anti-scraping mechanisms.
Customization: Customize delays based on the target website's sophistication and the type of data being scraped.
Geographical Location
Targeted Scraping: Select web scraping proxies in locations that are most relevant to the content you're trying to access or the market you're researching.
Diverse Locations: Maintain a diverse range of geographical locations in your proxy pool to access a wider variety of content and reduce the risk of geo-blocking.
Compliance: Ensure that the use of geographically targeted proxies complies with the legal and ethical standards of the regions involved.
How to Test Proxies for Web Scraping
There are several important proxy testing criteria, including reliability, security, and speed. Here’s how they can influence your web scraping process:
Proxy speed impacts timeout risks and unsuccessful requests, can use tools to measure load times and performance score. When testing proxies for web scraping, it's important to assess their speed, as well as to be mindful of timeout risks and the rate of unsuccessful requests. Here's how you can approach this:
Performance Tools: Use load time tools like cURL or fast.com to gauge speed, response time, and throughput of your proxy.
Target Site Testing: Test the proxies against the actual websites you plan to scrape to get a realistic measure of performance or detect delays.
Benchmarking: Compare the speed of different proxies to identify the fastest ones for your needs.
Timeout Settings: Adjust the timeout settings in your scraping configuration to balance between waiting for a response and moving on to the next request.
Error Handling: Implement robust error handling to retry failed requests with a different proxy or after a delay.
Monitoring: Continuously monitor the success rate of your proxies. A high rate of timeouts or failed requests can indicate an issue with the proxy's reliability or with the target website's anti-scraping measures.
Reliability
The reliability of proxies is a critical factor, especially when it comes to web scraping and other online activities that depend on consistent and uninterrupted service. Here's why proxy reliability is so important:
Consistent Performance: Reliable proxies ensure that your requests are forwarded to their intended destinations without interruption, providing a smooth and predictable performance.
Uptime: High reliability means that the web scraping proxy services are available when you need it, minimizing disruptions to your activities.
Trustworthiness: Just like you rely on a dependable friend, a reliable proxy gives you confidence that your data scraping or browsing activities will be successful.
Error Reduction: A reliable proxy reduces the chances of encountering errors or timeouts, which can compromise data collection and analysis.
Security
Choosing a secure proxy that prioritize data security and privacy is essential for several reasons:
Data Protection: Proxies with strong security measures can protect private and safe data from cyber threats like hacking and surveillance.
Anonymity: Secure proxies ensure that your IP address and browsing activities remain private, which is crucial when accessing sensitive information or conducting competitive research.
Trust: Using secure proxies can build trust with clients and stakeholders by demonstrating a commitment to protecting their data.
To perform SSL certificate checks and find security ratings, you can use security testing tools like:
Qualys SSL Labs: This service performs a deep analysis of the configuration of any SSL web server on the public Internet.
Bitsight Security Ratings: Bitsight provides an objective, data-driven lens to view the health of an organization’s cybersecurity program.
Rechecking web scraping proxies over time is important because the security landscape is constantly evolving, and what may be secure today might not be tomorrow. Another reason lies in compliance, as regular checks ensure that proxies remain compliant with the latest security standards and regulations.
How Many Proxies Do You Need for Web Scraping?
The number of proxies needed for web scraping can vary greatly depending on the scale of your scraping operation, the target websites, and the rate limits they impose. However, there is a general number of proxies formula that can help you estimate the number of proxies you might need:
The number of access requests depends on the number of pages you want to crawl and the frequency with which your scraper is crawling a website. The crawl rate refers to how many requests you intend to make per proxy before rotating to a new one.
As for the requests-per-second limits, it's recommended to avoid too many requests per second at a maximum to avoid overloading the server. This is considered good etiquette in web scraping and helps prevent your IP from being blocked by the target server. It's also important to implement a more sophisticated rate-limiting strategy that determines the amount of allowed requests per minute and includes random intervals between requests to mimic human behavior more closely.
Infatica is often recognized as a strong option for obtaining proxies for web scraping purposes. It offers a variety of proxy solutions that cater to the needs of businesses and individuals who require reliable and efficient web scraping capabilities:
Wide Range of Countries: Infatica's proxy service boasts a large pool of IP addresses from over 150 countries, providing users with the ability to perform geo-targeted scraping.
High Speed: Infatica's proxies are fast, which is crucial for efficient data scraping and processing.
Anonymity: We provide a high level of anonymity, ensuring that users can conduct their scraping activities without exposing their own IP address.
How to Set up Proxy for Web Scraping
Setting up proxy scraping involves several steps to ensure that your activities are efficient, secure, and respectful of the target website's policies. Here's a step-by-step guide to help you get started:
Get Infatica proxies: Go to the My Services section and open the available proxy package according to your tariff. In the Generate Proxy List section, enter the necessary settings. Choose the default proxy format, host:port:username:password.
Configure Proxy Settings: Input the proxy details into your scraping bot’s configuration. This usually includes the proxy IP, port, username, and password.
Script Modification: If you’re using a custom script, modify the HTTP request section to route through the proxy. In Python, this can be done using the requests library where you pass the proxy details in the proxies parameter.
Testing: After configuration, test the setup to ensure that the bot is correctly using the proxies. You can do this by making a request to a site like httpbin.org/ip to verify the IP address.
Monitor and Adjust: Continuously monitor your bot’s performance with the proxies. If you encounter errors or bans, adjust the proxy settings or rotation logic as needed.
Conclusion
Wrapping up, you've traversed the landscape of web scraping with a focus on web scraping proxy utilization. With these newfound strategies, you're ready to tackle data extraction challenges with enhanced expertise and tactical know-how.
Frequently Asked Questions
The optimal proxy for Google scraping are residential IP addresses, which offers genuine IP addresses and minimizes the risk of detection, ensuring a smoother and more successful scraping experience.
To prevent your proxies from getting banned, implement IP rotation, adhere to the target site's request rate limits, and introduce random intervals between requests to mimic human browsing patterns.
It is feasible to use the same IP address across multiple projects if they are not run simultaneously, which helps in managing resources while avoiding potential bans due to rate limit violations.
Utilize a proxy manager to regularly monitor your proxies' performance, checking for factors like uptime, response time, and the success rate of requests to maintain optimal operation.
IP masking is a technique used in web scraping to hide the scraper’s actual IP address, employing the proxy's IP to bypass web server restrictions and prevent detection.
To use a proxy for web scraping, configure your scraping tool to route requests through the proxy server, which anonymizes your traffic and helps avoid IP-based blocking.
For scraping in Python, residential, rotating, and datacenter proxies are commonly utilized, managed through libraries such as requests or scrapy, to facilitate efficient data collection.
Jan is a content manager at Infatica. He is curious to see how technology can be used to help people and explores how proxies can help to address the problem of internet freedom and online safety.
You can also learn more about:
Web scraping
Data Monitoring: How to Track Critical Changes and Make Smarter Decisions
Learn how continuous data monitoring helps businesses track competitor pricing, stock levels, and market trends – reliably and at scale.
Infatica updates
Infatica Expands Proxy Network to 40 Million IPs
Infatica expands its global proxy network to 40 million IPs, including 35 million residential addresses, enabling more reliable web scraping, automation, and data collection.
Integrations
How to Set Up Infatica Proxies in GeeLark
Step-by-step guide to connecting Infatica proxies with GeeLark for stable, geo-targeted mobile device environments.
Get In Touch
Have a question about Infatica? Get in touch with our experts to learn how we can help.















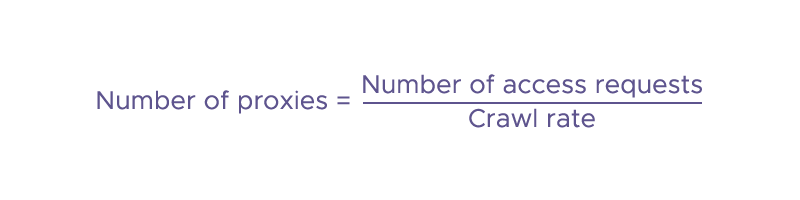





{kind=link}
{kind=link}