







Maintaining the relevance and accuracy of data is the top task for e-commerce aggregator websites. If the aggregator fails to do this , its main advantage disappears – people use aggregators to find the most relevant information in one place.
Web scraping techniques are the best way to ensure your aggregated data is up-to-date and accurate. To run scraping, you need specialized software, called a crawler. This bot visits the required websites, parses their data, and uploads this information to the aggregator website.
The problem is that very often the owners of the websites you want to scrape are not happy about this. If their data is presented on an aggregator website along with information from competitors, there is no need for the end-user visit this original website anymore. This harms sales. So, for this very reason ,website owners try to block crawling bots, which is easily understandable.
How websites block scraping bots
The companies that operate e-commerce websites try to prevent crawlers from parsing their websites' data. This is usually done by blocking requests from such bots based on an IP. Crawling software often uses so-called data center IPs, which are easy to detect and block.
Also, besides just blocking, website owners can trick bots by displaying fake and irrelevant information. For example, they can display prices that are higher or lower than reality, or altered goods descriptions.
One of the most common examples of this is in the airplane ticket industry. Here airlines and travel agencies often try to trick aggregators and show them different data based on the aggrogator’s IP.
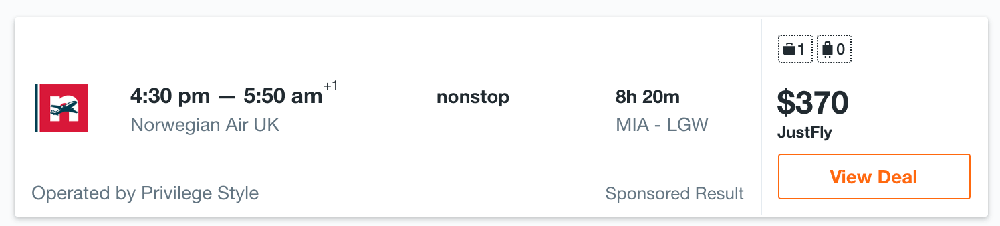
Let's look at a real use case by searching for an airplane ticket from Miami to London on a specific day. We've sent one request from an IP in Eastern Europe, with a second one sent through an IP in Asia.
Here is the price for the request from the Eastern European-based IP:
And here is the search result for the Asian IP:
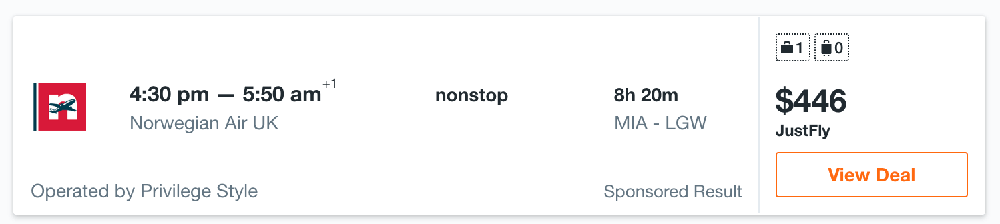
As you can see, the same ticket can display different prices. A difference of $76 is huge for just one ticket. Such situations are horrible for any aggregator website – if the aggregator displays the wrong information, there will be no reason to use it. Also, when the aggregator shows one price, if after clicking on it the user is forwarded to a website with a different price, this harms the project's reputation.
The solution: residential proxies
To avoid web scraping problems and blocks, you can use residential proxies. Datacenter IPs are assigned by hosting providers. It is not that hard to understand that the specific IP belongs to a particular provider. It can be done based on the ASN number, where this information is stored.
There are a lot of tools for automated ASN analysis, which are often integrated with antibot systems. As a result, crawlers are easily detected and blocked, or tricked by fake data.
Residential proxies can be helpful here. They use IP addresses assigned to regular users (homeowners) by their ISP. These addresses are marked in corresponding internet registries. Infatica is such a residential proxy.
If you use a residential proxy, all requests sent from that particular IP will be indistinguishable from the ones submitted by regular users. In this case, no one tries to block or trick potential customers, especially in the area of e-commerce.
As a result, using Infatica’s rotating proxies helps aggregators to ensure the accuracy and consistency of their data, while at the same time avoiding blocks and other problems.
More articles on how residential proxies are useful for business




{kind=link}
{kind=link}