






Article content

Denis Kryukov
6 min read
Distorting proxies were once a common tool for masking IP addresses and bypassing simple access restrictions. Let’s explore how distorting proxies work, see their limitations, examine why they no longer meet modern use cases, and compare them with today’s proxy alternatives.
How Distorting Proxies Work
At a technical level, distorting proxies act as intermediaries between a client and a destination website, relaying requests while modifying specific pieces of request metadata. The goal is not only to hide the original IP address, but to present altered identifying information that influences how the request is interpreted by the receiving server.
When a client sends a request through a distorting proxy, the proxy establishes its own connection to the target website. The website therefore sees the proxy’s network-level IP address as the source of the request. At the same time, the proxy injects or modifies HTTP headers that are commonly used to convey client information, such as X-Forwarded-For, X-Real-IP, or Via. These headers may contain a fabricated IP address, a partially masked value, or an address that does not match the actual connection source.
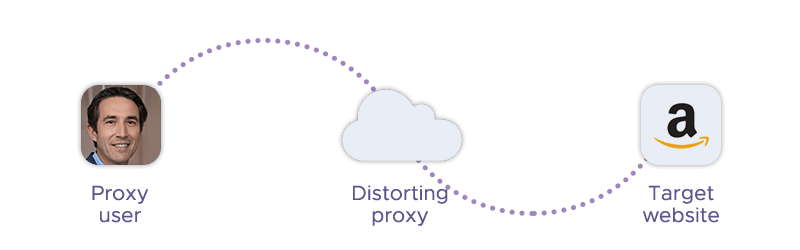
This dual signaling is the defining characteristic of distorting proxies. On one level, the TCP/IP connection originates from the proxy server. On another, the application-layer headers suggest a different client identity. In early web environments, many applications trusted these headers when logging client information or applying simple access controls, which made header manipulation an effective technique.
Implementation
Distorting proxies are typically implemented in one of two ways. Some are standalone proxy servers configured to rewrite headers automatically for all outbound traffic. Others are lightweight scripts or middleware layers that sit in front of a scraping or testing tool, modifying request headers before the request is sent through a standard proxy or server connection.
Because this approach focuses on altering request metadata rather than providing a genuinely different network identity, distorting proxies generally rely on a limited pool of IP addresses. Rotation, if available, is often basic and disconnected from reputation management, geographic accuracy, or session persistence.
The Real Problems With Distorting Proxies
While distorting proxies were once effective in environments with minimal traffic analysis, their design introduces several structural weaknesses that limit their usefulness today. Most of these issues stem from the fact that distorting proxies attempt to manipulate how a request appears rather than how it behaves at the network level.
Signal inconsistency
Modern websites analyze multiple layers of a request simultaneously, including the source IP, HTTP headers, TLS fingerprints, request timing, and behavioral patterns. When a proxy presents a network-level IP that conflicts with application-layer headers, these discrepancies can immediately raise suspicion and trigger blocks or challenges.
Easy detectability

Headers commonly altered by distorting proxies, such as X-Forwarded-For or Via, are well-known to anti-bot and fraud-prevention systems. If these headers contain implausible values, private IP ranges, or mismatches with the observed connection, the request can be flagged without further analysis. In some cases, the mere presence of certain headers is enough to indicate proxy usage.
Poor IP reputation and reuse
Because they often rely on small, static pools of server IPs, traffic patterns become predictable over time. Repeated requests from the same infrastructure, even with varying header values, quickly accumulate negative reputation, leading to rate limiting or outright bans.
Scalability
Header manipulation does not address core requirements such as reliable rotation, geographic diversity, or session control. As data collection needs grow, distorting proxies struggle to maintain consistency across thousands or millions of requests, especially when targeting platforms with adaptive defenses.
Operational and compliance concerns
Manually altering request metadata can introduce configuration errors, logging inconsistencies, and unclear attribution of traffic sources. For teams operating at scale or in regulated environments, this lack of transparency can complicate monitoring, debugging, and compliance efforts.
Why Distorting Proxies No Longer Work for Modern Use Cases
Modern websites and platforms no longer rely on single indicators, such as an IP address or a request header, to determine whether traffic is legitimate. Instead, they evaluate a combination of network signals, behavioral patterns, and historical reputation.
In web scraping and data extraction, platforms actively correlate IP reputation with request frequency, navigation paths, and response handling. Distorting proxies may alter header values, but repeated traffic from the same underlying infrastructure quickly becomes recognizable. As a result, scraping sessions often fail after a short period, requiring constant manual adjustments with diminishing returns.
For SERP monitoring and SEO analysis, consistency and geographic accuracy are critical. Search engines validate location signals across multiple layers, including IP geolocation, DNS behavior, and latency patterns. Header-based IP manipulation cannot reliably reproduce these signals, leading to inaccurate results, frequent captchas, or blocked requests.
In price intelligence and market research, especially in travel, e-commerce, and on-demand services, platforms commonly personalize pricing based on location, device type, and traffic history. Distorting proxies struggle to maintain stable sessions or authentic geographic profiles, making it difficult to collect comparable pricing data across regions without detection.
Ad verification and brand protection workflows face similar challenges. Many advertising platforms aggressively filter traffic that shows inconsistent origin data or abnormal access patterns. Requests routed through distorting proxies are more likely to be flagged as non-human or automated, reducing coverage and reliability.
Finally, account-based and session-dependent use cases expose one of the biggest weaknesses of distorting proxies. Login flows, shopping carts, and persistent user sessions require a stable, trustworthy IP identity over time, which is exactly what ISP proxies provide. Because distorting proxies do not provide genuine session continuity or clean reputation management, they are poorly suited for these scenarios.
Distorting Proxies vs Modern Proxy Types
| Feature / Capability | Distorting Proxies | Datacenter Proxies (Shared/Dedicated) | Residential Proxies | Static ISP Proxies | Mobile Proxies |
|---|---|---|---|---|---|
| IP authenticity | Low – relies on header manipulation rather than real IP identity | Medium – real server IPs, identifiable as datacenter traffic | High – real residential user IPs | High – ISP-issued, fixed residential IPs | Very high – real mobile carrier IPs |
| Header consistency | Poor – frequent mismatches between headers and network IP | Good | Excellent | Excellent | Excellent |
| Detection resistance | Low – easily flagged by modern anti-bot systems | Medium – depends on target and use case | High | High | Very high |
| IP reputation management | Minimal or none | Managed, but reputation can degrade at scale | Actively managed, large pools | Stable, long-term reputation | Shared carrier reputation |
| Rotation control | Limited or manual | Flexible, especially with shared pools | Highly flexible, session- or request-based | Fixed IP per session | Controlled rotation via carrier NAT |
| Session persistence | Weak or unreliable | Good, especially with dedicated IPs | Configurable | Excellent, designed for long sessions | Moderate |
| Geographic accuracy | Unreliable | Moderate | High (country, city, region-level) | High | Medium |
| Scalability | Poor | High | Very high | Medium | Medium |
| Typical block rate | High | Medium | Low | Low | Very low |
| Best suited for | Basic testing, legacy setups | High-volume scraping, speed-focused tasks | Web scraping, SERP monitoring, price intelligence | Account-based workflows, logins, long sessions | App-like behavior, sensitive targets |
Moving Beyond Distorting Proxies
If your use case has outgrown header manipulation and short-lived workarounds, modern proxy infrastructure offers a more sustainable path forward. From high-volume datacenter traffic to residential, static ISP, IPv6, and mobile IPs, authentic proxy networks are designed to match real-world browsing behavior and evolving platform defenses.
Explore proxy solutions built for modern data collection – without relying on request distortion.
Frequently Asked Questions
A distorting proxy routes traffic through an intermediary server while modifying HTTP headers to present a false or misleading client IP. The actual network-level IP and the header information often do not match.
Anonymous proxies hide the client’s real IP without altering request headers in obvious ways. Distorting proxies actively manipulate headers, which creates inconsistencies that modern websites can easily detect.
In most modern environments, distorting proxies are unreliable for scraping. Platforms analyze IP reputation, behavior, and header consistency, making header-based IP manipulation ineffective and prone to blocking.
Websites cross-check multiple signals, including IP origin, headers, TLS fingerprints, and behavior. When these signals conflict, as they often do with distorting proxies, requests are quickly flagged or blocked.
What should I use instead of distorting proxies?
Modern proxy types such as datacenter, residential, static ISP, IPv6, and mobile proxies provide authentic IP identities, better reputation management, and consistent behavior suited for today’s detection systems.



{kind=link}
{kind=link}