






Article content


Denis Kryukov
7 min read
Web scraping can be done in two main ways – synchronously or asynchronously – and the difference between them can dramatically affect your project’s speed, scalability, and efficiency. Let’s compare both approaches, explain how they work, and help you choose the best method for your data extraction goals!
How Asynchronous Web Scraping Works
Asynchronous web scraping relies on a programming model that lets multiple tasks run concurrently instead of waiting for one another to complete. In traditional scraping, the program pauses after sending each request – but with asynchronous logic, it can send hundreds of requests at once and process the results as soon as they arrive.
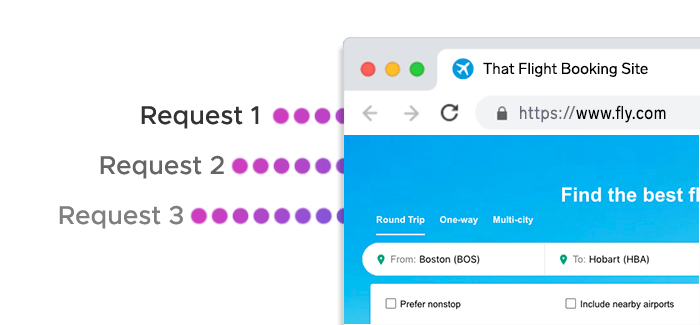
This efficiency comes from non-blocking I/O – a core idea behind asynchronous programming.
The Event Loop: The Heart of Async Operations
At the center of asynchronous scraping lies the event loop, a control structure that manages multiple tasks at the same time.
When the scraper sends an HTTP request, instead of waiting for a response, the event loop registers the task and immediately continues to send more requests. As soon as responses start coming back, the loop processes them one by one.
Async Libraries for Web Scraping
Python offers several libraries designed for asynchronous workflows:
- Asyncio – The built-in Python library that provides the foundation for writing asynchronous code.
- aiohttp – An HTTP client built on top of Asyncio, ideal for handling many concurrent web requests efficiently.
- Trio – A modern alternative with simpler error handling.
- Scrapy (Async Mode) – The popular scraping framework that now supports asynchronous operations out of the box.
Example: A Simple Asynchronous Scraper in Python
Below is a simplified example showing how asynchronous scraping works using aiohttp and asyncio.
import aiohttp
import asyncio
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3"
]
async def fetch(session, url):
async with session.get(url) as response:
html = await response.text()
print(f"Fetched {url} with status {response.status}")
return html
async def main():
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
await asyncio.gather(*tasks)
asyncio.run(main())
Here’s what happens:
- The script opens an asynchronous HTTP session.
- It sends multiple requests almost simultaneously.
- As each page responds, the result is processed immediately – no waiting for others.
This structure lets a scraper handle hundreds or even thousands of pages per minute, depending on concurrency settings and network limits.
Benefits of Asynchronous Scraping
The biggest reason developers embrace asynchronous web scraping is speed – but that’s just the beginning. Async techniques reshape how scrapers perform, scale, and manage resources, especially in data-heavy environments where every second and request counts.
Dramatically Faster Data Collection
Asynchronous scraping lets multiple requests run at once, turning what used to be a sequential process into a parallel one.
When hundreds of pages are fetched simultaneously, total scraping time can drop from hours to minutes – ideal for real-time data collection, market monitoring, and price tracking.
This performance boost is particularly useful for businesses handling large-scale or time-sensitive datasets, such as e-commerce product listings or SERP results.
Better Resource Efficiency
Traditional scrapers often waste time waiting for servers to respond, leaving CPU and bandwidth underused. Async scrapers, however, make the most of every available system resource by overlapping network and computation tasks. This efficiency means:
- Fewer servers needed to achieve the same throughput
- Lower operational costs
- More predictable performance even under heavy loads
Improved Scalability
Asynchronous scraping scales naturally. Once you build an async scraper, increasing concurrency – i.e., how many URLs you scrape at once – is as simple as adjusting a configuration parameter. This makes it ideal for:
- Enterprise-scale data extraction projects
- Continuous data feeds or monitoring tools
- Large website crawls spanning thousands of domains
However, as concurrency increases, websites may impose rate limits or block excessive traffic – which is why pairing async scrapers with a rotating proxy network is essential.
Reduced Latency and Faster Insights
Async scrapers not only collect data faster but also return insights sooner. For businesses tracking competitors’ prices, monitoring job listings, or aggregating news, milliseconds matter – and asynchronous logic delivers that edge.
By processing responses as soon as they arrive, your scraper provides near real-time visibility, enabling quicker analysis and decision-making.
Enhanced Reliability and Error Handling
When dealing with thousands of simultaneous requests, some will inevitably fail due to timeouts, captchas, or server issues. Asynchronous scraping makes it easier to retry failed requests, balance workloads, and keep data pipelines running smoothly.
Challenges and Best Practices
As powerful as asynchronous web scraping can be, it comes with its own set of challenges.
Managing Concurrency Levels
The key to asynchronous scraping lies in balance. Sending too few requests wastes potential speed gains, while sending too many can overwhelm your system or target servers.
Best practice: Start with a moderate concurrency limit (e.g., 50–100 simultaneous connections) and gradually increase it while monitoring response times and error rates. Tools like asyncio.Semaphore or Scrapy’s concurrency settings make this easy to control.
Handling Errors and Timeouts Gracefully
When sending hundreds of concurrent requests, timeouts, slow responses, or broken connections are inevitable. Without proper handling, these errors can cascade and cause data loss.
Best practice: Implement automatic retries with exponential backoff (waiting longer between failed attempts), and use asyncio.wait_for() to define timeout limits. Logging every failed request also helps identify recurring issues.
Avoiding Detection and CAPTCHAs
High-frequency, pattern-like scraping behavior can quickly raise suspicion. Many websites employ anti-bot systems like Cloudflare or reCAPTCHA that detect repetitive access from a single IP address.

Best practice: Use a rotating proxy network that distributes requests across different IPs and locations. Residential proxies, in particular, provide natural browsing patterns that significantly reduce the risk of detection. This approach also ensures continuous uptime, even if a subset of IPs gets blocked.
Monitoring and Scaling Infrastructure
As your scraper grows, you’ll need visibility into performance: how many requests succeed, how many fail, and how fast data is being collected.
Best practice: Implement real-time monitoring and metrics. Track error rates, proxy usage, and response times to quickly spot issues. Scaling async scrapers often means scaling infrastructure – using cloud environments and load balancing between multiple machines.
Data Consistency and Synchronization
When handling asynchronous tasks, responses don’t always arrive in the same order as requests. Without proper management, this can lead to mismatched or incomplete datasets.

Best practice: Assign a unique identifier to each URL or task, store responses in a structured format (e.g., JSON or a database), and handle post-processing after all requests are complete. Async frameworks like Scrapy or aiohttp make task coordination more predictable.
Async Scraping + Proxies: The Winning Combination
Without the right network setup, high-concurrency requests can quickly trigger anti-bot systems or rate limits. That’s where proxies become essential.
By distributing requests across multiple IP addresses, proxies allow scrapers to operate safely and reliably at scale. Each request appears to come from a different location, reducing the likelihood of blocks and enabling parallel data collection across hundreds or thousands of URLs.
Why Infatica’s Rotating Proxies Excel
Infatica’s rotating proxy network is built to handle high-concurrency scraping without interruptions:
- Automatically rotates IPs to avoid detection
- Offers a mix of residential and datacenter IPs for flexible targeting
- Provides global coverage, ensuring access to geo-restricted content
This infrastructure ensures your asynchronous scraper runs smoothly, maintains high success rates, and collects large datasets efficiently.
Detailed Comparison Table
| Feature / Aspect | Synchronous Scraping | Asynchronous Scraping |
|---|---|---|
| Request Handling | Sequential – one request at a time | Concurrent – multiple requests handled simultaneously |
| Execution Speed | Slower, especially for large datasets | Faster, handles hundreds/thousands of requests efficiently |
| Resource Utilization | CPU/network often idle while waiting | Efficient use of CPU and network with non-blocking I/O |
| Code Complexity | Simple and easy to implement | Moderate to high; requires async programming and libraries |
| Error Handling | Easier to debug and track failures | Needs careful handling of timeouts, retries, and order of responses |
| Scalability | Limited; scaling requires more servers or threads | High; concurrency can be increased to handle large-scale scraping |
| Use Cases | Small projects, testing, or single-page scraping | Large datasets, real-time monitoring, or high-frequency scraping |
| Infrastructure Requirements | Minimal; can run on a single machine | May require more advanced setup, especially for very high concurrency |
| Risk of Blocking | Lower for small-scale scraping | Higher if requests are not distributed; mitigated with proxies |
| Integration with Proxies / APIs | Optional; often manual setup needed | Highly recommended for stability and speed; works well with rotating proxies or managed scraping APIs |
Frequently Asked Questions
Synchronous scraping handles one request at a time, waiting for each response. Asynchronous scraping sends multiple requests concurrently, processing results as they arrive, which significantly improves speed and efficiency for large-scale data collection.
Asynchronous scraping is faster for large websites because it executes many requests concurrently. Synchronous scraping waits for each request sequentially, making it inefficient for scraping hundreds or thousands of pages.
Yes. Python libraries like Asyncio, aiohttp, or Scrapy in async mode facilitate non-blocking, concurrent requests. These tools handle multiple connections efficiently, making async scraping both practical and scalable.
Absolutely. Proxies distribute requests across multiple IPs, reducing the risk of blocks or throttling during high-concurrency scraping. Residential and datacenter proxies integrate well with async scrapers, ensuring reliable, uninterrupted data collection.
If you want faster deployment, minimal coding, and built-in proxy rotation and error handling, Infatica's Web Scraper API is ideal. DIY async scrapers offer more control but require infrastructure, concurrency management, and ongoing maintenance.






{kind=link}
{kind=link}