






Article content


Jan Wiśniewski
13 min read
User agents are short strings of data – but they still hold severe importance for any web scraping pipeline: They can help you encounter less CAPTCHAs and collect data more consistently. In this article, we’re taking a closer look at most common user agents: We’ll explore how user agents work and how to use them effectively.
What Is a User Agent?
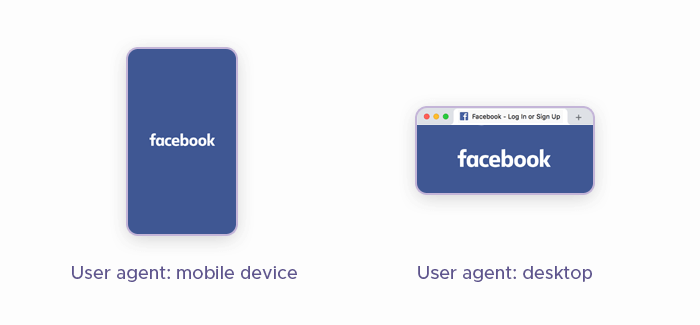
A user agent is a string that a web browser or other client application sends to a web server to identify itself. The UA string contains various device identification data, such as browser type, operating system, software versions, and device type. Web servers use this information to deliver content in the most appropriate user agent header format for the client.
How Websites Use User Agents for Identification
Content delivery optimization: Most websites can serve different layouts or styles based on the user agent. For example, a mobile user agent might trigger the website to serve a mobile-friendly version with touch-friendly navigation and simplified content. Additionally, certain features or optimizations may only be available or needed for specific browsers. For instance, a website might use a different method for rendering graphics on Google Chrome compared to Firefox.
Analytics and logging: User agents help in understanding the types of devices and browsers visitors are using. This information is valuable for website analytics to optimize content and improve user experience. Also, data on user agents can be used to track the popularity of different browsers and operating systems over time.

Access control and security: Websites can detect and block known malicious bots and known web scrapers based on their user agent strings. Some sites maintain lists of known bad user agents to automatically deny access. User agents can be used in conjunction with IP addresses to enforce rate limits. If excessive requests are detected from a particular user agent, the server might slow down or block access temporarily.
Feature support and compatibility: Web servers identify the browser, so they can enable or disable features that are known to work or fail in specific environments. For instance, a site might avoid using a particular HTML5 feature on an older browser that doesn’t support it. Furthermore, websites can load additional scripts or polyfills to support features in older browsers identified by its user agent string.
Why Is a User Agent Important for Web Scraping?
Content negotiation: Websites often serve different content based on the device and browser. For example, mobile devices may receive a mobile-optimized version of the site, while desktop browsers get a more feature-rich version. By identifying as a specific browser or device, web scraping tools can ensure it receives the correct version of the content.
Tailoring user experience: Some websites customize the user experience based on the user agent. This includes things like enabling or disabling certain features, changing layouts, and adjusting the presentation to better suit the identified client.
Differentiating human users from bots: By analyzing user agents, websites can differentiate between human users and web scraping bots. They may serve CAPTCHAs or other challenges to suspected bots based on its user agent header
Avoiding detection: Websites often look for an unusual or generic user agent as an indicator of scraping activity. User agent switching that mimics a real browser helps web scrapers avoid detection and blocking.
Respecting website terms of service: Some websites explicitly forbid data extraction in their terms of service but allow access to most web browsers. Using a legitimate user agent helps scrapers respect these boundaries and reduce the risk of legal issues.
Content variations: Websites may serve different content to different devices or browsers. For example, a news site might serve more text-based content to mobile devices and media-rich content to desktops. Using the appropriate user agent ensures the scraper gets the desired version of the content. Different user agents can access different web content, allowing scrapers to customize their requests based on the desired content and target audience.
Testing and validation: By simulating a different user agent, scrapers can test how the target website behaves across various browsers and devices. This is particularly useful with developer tools for understanding cross-browser compatibility and device-specific issues.
How to Check User Agents?
In order to check user agents, websites analyze the User-Agent header in the HTTP request. This process helps them identify the type of client making the request and respond accordingly. Here’s how different web pages check the user agent header:
- Receiving the request: When a client (browser, scraper, etc.) sends an HTTP request to a web server, it includes various headers, including the User-Agent.
- Extracting the user-agent header: The server reads the User-Agent header from the request to understand the client's identity.
- Analyzing the user-agent string: The server parses the User-Agent string to identify the browser, operating system, device type, and sometimes even the version of the browser.
- Responding appropriately: Based on the user agent, the server can: serve different content (e.g., mobile vs. desktop), allow or block requests (e.g., blocking known bots), or apply rate limiting or other access controls.
Below is a Python code snippet that mimics the functionality of a web server checking the user agent string. This example uses the Flask framework to create a simple web server that checks the User-Agent headers from incoming requests:
from flask import Flask, request, jsonify
app = Flask(__name__)
# List of known user agents to block
blocked_user_agents = [
'BadBot/1.0', # Example of a known bad bot user agent
'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' # Example of a known good bot user agent
]
@app.route('/')
def check_user_agent():
user_agent = request.headers.get('User-Agent', '')
# Log the user agent
print(f"User-Agent: {user_agent}")
# Check if the user agent is blocked
if user_agent in blocked_user_agents:
return jsonify({"message": "Access Denied"}), 403
# Respond based on the type of user agent
if 'Mobile' in user_agent or 'Android' in user_agent:
return jsonify({"message": "Mobile Content"}), 200
elif 'Windows' in user_agent or 'Macintosh' in user_agent:
return jsonify({"message": "Desktop Content"}), 200
else:
return jsonify({"message": "Generic Content"}), 200
if __name__ == '__main__':
app.run(debug=True)
How to Change Your User Agent?
Changing your user agent is a common technique in web scraping efforts to mimic different browsers or devices and avoid detection. When making HTTP requests in Python, you can change your user agent header by modifying User-Agent headers in your request. This can be done using libraries such as requests, urllib, or selenium. Here's how you can set a user agent, along with a Python code snippet and an explanation of how it works.
import requests
# Define the URL you want to scrape
url = 'https://example.com'
# Define the headers with a custom User-Agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# Send the HTTP request with the custom headers
response = requests.get(url, headers=headers)
# Print the response content
print(response.content)
Which User Agents Are Commonly Used for Scraping Websites?
Here are some common user agents for different browsers and devices. While it may be hard to pinpoint the “best user agents”, these would be a safe pick.
Google Chrome, Desktop (Windows 10):
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36Google Chrome, Mobile (Android):
Mozilla/5.0 (Linux; Android 10; SM-G975F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Mobile Safari/537.36Mozilla Firefox, Desktop (Windows 10):
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0Mozilla Firefox, Mobile (Android):
Mozilla/5.0 (Android 10; Mobile; rv:89.0) Gecko/89.0 Firefox/89.0Safari, Desktop (macOS):
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15Safari, Mobile (iOS):
Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/604.1Microsoft Edge, Desktop (Windows 10):
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64Bots/Crawlers (Googlebot):
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)Bots/Crawlers (Bingbot):
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)How to Avoid Getting Your UA Banned
There are multiple approaches towards maintaining unique user agent strings. Let’s take a closer look at four popular methods:
1. Rotate User Agents
Rotating user agents is an effective technique to avoid getting your user agent banned while scraping websites. As you rotate user agents in your HTTP requests, you can simulate traffic from multiple devices and browsers, making it harder for websites to detect and block your scraping activity.
- Diversifying requests: Thanks to user agent rotation, your requests appear to come from various browsers and devices, reducing the likelihood that a single user agent will be flagged for suspicious activity.
- Avoiding patterns: Consistently using the same user agent can create a detectable pattern. Rotating them introduces randomness, making it harder for anti-scraping mechanisms to identify your scraper.
- Evading detection algorithms: Some websites use machine learning algorithms to detect scraping based on user agent patterns. Rotate user agents to bypass these algorithms.
- Reducing rate limiting: Websites may impose rate limits based on the user agent header. Rotating user agents can distribute the requests across different identities, potentially bypassing these limits.
Here’s a Python code snippet that demonstrates how to implement rotation of the user agent string using the requests library. This example will fetch a web page using different user agents randomly selected from a predefined list.
import requests
from random import choice
# Define the URL you want to scrape
url = 'https://example.com'
# List of different user agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/604.1',
'Mozilla/5.0 (Linux; Android 10; SM-G973F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Mobile Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
# Function to make a request with a random user agent
def fetch_page_with_random_user_agent(url):
# Choose a random user agent from the list
user_agent = choice(user_agents)
# Set up the headers with the chosen user agent
headers = {
'User-Agent': user_agent
}
# Send the HTTP request with the custom headers
response = requests.get(url, headers=headers)
# Print the chosen user agent and the response status
print(f"Used User-Agent: {user_agent}")
print(f"Response Status Code: {response.status_code}")
return response.content
# Example usage
for _ in range(5): # Fetch the page 5 times with different user agents
content = fetch_page_with_random_user_agent(url)
# Process the content as needed
2. Keep Random Intervals Between Requests
Adding random intervals between requests is another effective method to avoid detection and banning while scraping websites. By introducing randomness in the timing of your requests, you can mimic human browsing behavior, making it harder for websites to detect your scraping activity as automated.
- Mimicking human behavior: Human browsing behavior is not consistent and has natural pauses. Random intervals between requests simulate this behavior, making your scraper appear more like a real user.
- Reducing pattern detection: Consistent request patterns can be easily detected by anti-scraping mechanisms. Random intervals introduce variability, making it harder to identify scraping activity.
- Evasion of bot detection: Some websites employ sophisticated algorithms to detect bots based on the frequency and regularity of requests. Random intervals can help evade these detections.
import requests
import time
import random
# Define the URL you want to scrape
url = 'https://example.com'
# List of different user agents
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/604.1',
'Mozilla/5.0 (Linux; Android 10; SM-G973F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Mobile Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
# Function to make a request with a random user agent and random interval
def fetch_page_with_random_delay(url):
# Choose a random user agent from the list
user_agent = random.choice(user_agents)
# Set up the headers with the chosen user agent
headers = {
'User-Agent': user_agent
}
# Send the HTTP request with the custom headers
response = requests.get(url, headers=headers)
# Print the chosen user agent and the response status
print(f"Used User-Agent: {user_agent}")
print(f"Response Status Code: {response.status_code}")
return response.content
# Example usage
for _ in range(5): # Fetch the page 5 times with different user agents
# Fetch the page with random user agent
content = fetch_page_with_random_delay(url)
# Process the content as needed
# Introduce a random delay between 1 and 5 seconds
delay = random.uniform(1, 5)
print(f"Sleeping for {delay:.2f} seconds")
time.sleep(delay)
3. Use Up-to-date User Agents
Update user agents to make use of modern ones – and you’ll avoid getting banned while using a web scraping API. Modern websites often maintain lists of known outdated UAs or those associated with bots and scrapers. By using an up-to-date user agent, you can blend in with legitimate traffic, reducing the likelihood of being flagged or blocked.
- Avoiding known bot user agents: Websites often block or monitor requests from outdated or commonly used bot UA strings. Using the latest user agents helps you avoid these lists.
- Mimicking real users: Up-to-date user agents reflect current browser versions that real users are likely to be using, making your scraping activity less suspicious.
- Staying compatible: Some websites serve different content or features based on the user agent. Using most common user agents that are modern ensures that you receive the same content as a real user.
- Avoiding detection: Anti-scraping mechanisms are often updated to recognize outdated user agents. Keeping your user agents up-to-date helps evade these detections.
import requests
import random
# URL to fetch the latest user agents (example URL, you might need to use an actual service or maintain your own list)
latest_user_agents_url = 'https://api.example.com/latest-user-agents'
# Function to get the latest user agents
def get_latest_user_agents():
response = requests.get(latest_user_agents_url)
if response.status_code == 200:
return response.json()['user_agents']
else:
# Fallback to a predefined list if fetching fails
return [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/604.1',
'Mozilla/5.0 (Linux; Android 10; SM-G973F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Mobile Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
# Function to make a request with a random up-to-date user agent
def fetch_page_with_latest_user_agent(url, user_agents):
# Choose a random user agent from the list
user_agent = random.choice(user_agents)
# Set up the headers with the chosen user agent
headers = {
'User-Agent': user_agent
}
# Send the HTTP request with the custom headers
response = requests.get(url, headers=headers)
# Print the chosen user agent and the response status
print(f"Used User-Agent: {user_agent}")
print(f"Response Status Code: {response.status_code}")
return response.content
# Get the latest user agents
user_agents = get_latest_user_agents()
# Example usage
url = 'https://example.com'
for _ in range(5): # Fetch the page 5 times with different user agents
content = fetch_page_with_latest_user_agent(url, user_agents)
# Process the content as needed
4. Custom User Agents
Using custom user agents can be another effective method to avoid detection and banning while web scraping. By creating custom user agent strings, you can tailor your requests to appear as if they are coming from specific devices or browsers, and even include additional metadata that can further obscure your scraping activity.
- Tailoring to specific needs: Custom user agents can be designed to mimic specific browsers, operating systems, and devices – this way, the web server identifies web scraping activity less frequently.
- Adding complexity: By including additional metadata in your user agent strings, you can introduce variability that can confuse detection algorithms.
- Avoiding known patterns: Custom user agents can help you avoid detection by steering clear of commonly blocked or flagged user agent information.
- Evading simple filters: Websites that use simple filters to block other user agents may not recognize your custom user agents, allowing your requests to pass through.
import requests
import random
# Define the URL you want to scrape
url = 'https://example.com'
# List of custom user agents
custom_user_agents = [
'CustomUserAgent/1.0 (Windows NT 10.0; Win64; x64) CustomBrowser/91.0.4472.124',
'CustomUserAgent/1.0 (Macintosh; Intel Mac OS X 10_15_7) CustomBrowser/14.0.3',
'CustomUserAgent/1.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) CustomBrowser/14.1.1',
'CustomUserAgent/1.0 (Linux; Android 10; SM-G973F) CustomBrowser/79.0.3945.79',
'CustomUserAgent/1.0 (Windows NT 10.0; WOW64) CustomBrowser/45.0'
]
# Function to make a request with a custom user agent
def fetch_page_with_custom_user_agent(url):
# Choose a random custom user agent from the list
user_agent = random.choice(custom_user_agents)
# Set up the headers with the chosen user agent
headers = {
'User-Agent': user_agent
}
# Send the HTTP request with the custom headers
response = requests.get(url, headers=headers)
# Print the chosen user agent and the response status
print(f"Used Custom User-Agent: {user_agent}")
print(f"Response Status Code: {response.status_code}")
return response.content
# Example usage
for _ in range(5): # Fetch the page 5 times with different custom user agents
content = fetch_page_with_custom_user_agent(url)
# Process the content as needed
Frequently Asked Questions
The best user agent for scraping is hard to determine, but generally, it identifies the client software making the request to a web server, typically mimicking a browser to avoid detection and blocks.
Most common user agents include Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36.
A user agent is used in web scraping to mimic a real browser, helping to avoid detection, blocking, or throttling by websites that may restrict automated requests.
The user agent string provides information about the client's software, such as the browser type, operating system, and version, which helps servers tailor responses for compatibility.
Yes, you can fake a user agent by manually setting the user agent string in your HTTP requests to mimic different browsers or devices, enhancing your scraping efforts.





{kind=link}
{kind=link}