- Products & Pricing
- Client Profiles
- Company
- Log In
- Contact Sales
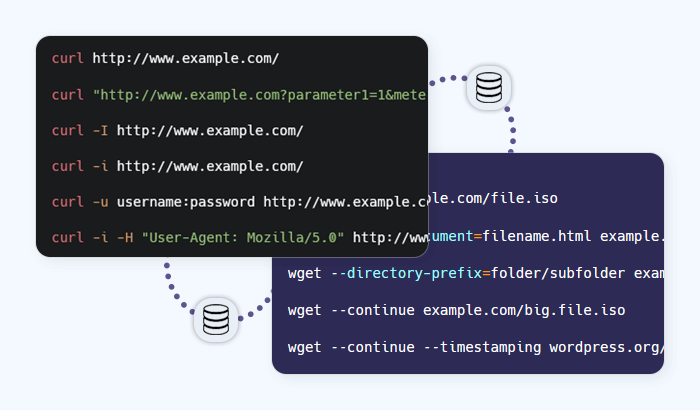
A collection of resources dedicated to web scraping: How to do it effectively and better understand possible limitations. Also covers web crawling.

Learn how automated data collection helps retailers optimize pricing, track competitors, and understand customer trends. Discover how Infatica’s Web Scraping API delivers clean, real-time retail data at scale.