






Article content


Jovana Gojkovic
7 min read
In today’s data-driven world, businesses often need to extract information from platforms that don’t provide an easy way to access it. While modern solutions like APIs and structured web scraping tools are widely used, there’s also a technique called screen scraping.
Even though screen scraping is still applied in specific use cases, it has significant drawbacks compared to modern web scraping methods. In this article, we’ll explain what screen scraping is, how it works, its advantages and limitations, and why businesses today often turn to web scraping and proxies as more reliable alternatives.
What Is Screen Scraping?
Screen scraping is the process of extracting data directly from the visual display of a computer program rather than from its underlying code or a structured data source. In simple terms, it’s about “reading” what’s on the screen – much like a person copying and pasting text, but automated through software.
Historically, screen scraping emerged as a way to bridge gaps between older, legacy systems and modern applications. Many early financial systems, for example, didn’t offer APIs or direct database access, so companies relied on screen scraping to transfer or integrate information. Typical uses of screen scraping include:
- Accessing legacy systems that lack modern interfaces.
- Migrating data from outdated applications.
- Automating repetitive tasks that involve manual data entry.
- Integrating systems where APIs are unavailable.
While it solved critical problems in the past, screen scraping has become less common today. With the growth of web scraping, APIs, and cloud-based integrations, screen scraping is now considered a last-resort solution when no other access methods are available.
How Does Screen Scraping Work?
At its core, screen scraping automates what a human user would see and do on a screen. Instead of accessing structured data directly, it captures the output displayed by an application and converts it into a usable format. The process typically involves several steps:
- Capturing the screen output: Specialized software or scripts read the visual elements of a program or web page – this could include text, numbers, tables, or even images.
- Interpreting the content: The captured information is parsed using techniques such as pattern recognition or Optical Character Recognition (OCR) to turn raw screen data into structured text.
- Data transformation: Once interpreted, the data is cleaned, formatted, and organized into a more useful structure, such as a spreadsheet, database, or JSON file.
- Integration with other systems: Finally, the processed data can be used for reporting, analytics, or feeding into another application.
Benefits of Screen Scraping
Despite being considered an outdated method, screen scraping still offers certain advantages that explain why some businesses continue to rely on it.
Access to legacy systems: Many older applications lack APIs or modern data export features. Screen scraping provides a way to extract data from these systems without modifying their source code.
Quick implementation: In cases where a fast solution is needed, screen scraping can be set up relatively quickly compared to building a custom integration.
Automation of repetitive tasks: Tasks that would otherwise require manual copying and pasting can be automated, saving time and reducing the risk of human error.
Low technical barrier: Basic screen scraping can often be achieved with widely available automation tools, making it accessible to non-technical teams.
Flexibility of sources: Since it captures visual output, screen scraping can be applied to virtually any system or platform, even if no direct data access is possible.
Drawbacks and Risks of Screen Scraping
While screen scraping can be useful in certain scenarios, it comes with significant limitations and risks that often outweigh its benefits:
Fragility and instability: Screen scraping depends on the exact layout of a user interface. Even minor changes – like moving a button or updating a font – can break the entire scraping process.
Limited scalability: Because screen scraping reads data visually, it’s much slower than structured data extraction methods. This makes it unsuitable for large-scale or real-time data needs.
Accuracy issues: Screen scraping often relies on Optical Character Recognition (OCR) and pattern recognition, which can misinterpret characters or misread layouts, leading to data quality problems.
Legal and compliance risks: Extracting data without permission may violate terms of service, intellectual property laws, or data privacy regulations. Businesses using screen scraping must carefully evaluate these risks.
High maintenance costs: Maintaining screen scraping systems requires frequent updates to keep up with software or interface changes. Over time, this becomes resource-intensive and inefficient.
Screen Scraping vs. Web Scraping
While both techniques aim to extract data, they differ greatly in how they operate and in their practical applications:
| Aspect | Screen Scraping | Web Scraping |
|---|---|---|
| Data Source | Extracts data visually from the user interface (what’s displayed on the screen). | Extracts data directly from underlying HTML, APIs, or structured content. |
| Stability | Fragile – breaks easily if the interface changes. | Stable – minor site changes rarely disrupt the process. |
| Speed & Scalability | Slow and limited, not suitable for large datasets. | Fast, scalable, and capable of handling millions of requests. |
| Accuracy | Relies on OCR/pattern recognition, prone to errors. | Direct access to structured data ensures higher accuracy. |
| Maintenance | High – frequent updates required when UI changes. | Low – scraping scripts need fewer adjustments. |
| Compliance | Higher legal and ethical risks; harder to stay compliant. | Easier to comply with data-use policies, especially when combined with proxies. |
| Use Cases | Legacy systems, niche integrations, quick one-off tasks. | Market research, pricing intelligence, SEO monitoring, lead generation, data-driven analytics. |
Modern Alternatives to Screen Scraping
As technology evolved, more reliable and scalable methods of accessing data have replaced screen scraping. These alternatives provide faster, more accurate results while reducing compliance and maintenance concerns.
APIs (Application Programming Interfaces): Many platforms now offer APIs that allow developers to directly access structured data. APIs are the most stable and efficient way to interact with a system, but they are not always available or may have strict usage limits.
A Simple Guide to APIs: What They Are and How to Use Them
A beginner’s guide to APIs, including how they work, common use cases, and how proxies enhance API-based data collection and web scraping.
 Denis Kryukov
Denis Kryukov
Web scraping: Web scraping extracts information from the underlying HTML code of web pages rather than from what is displayed on the screen. It is faster, more accurate, and can scale to millions of requests. With the help of proxies, businesses can overcome restrictions such as rate limits and geo-blocking.
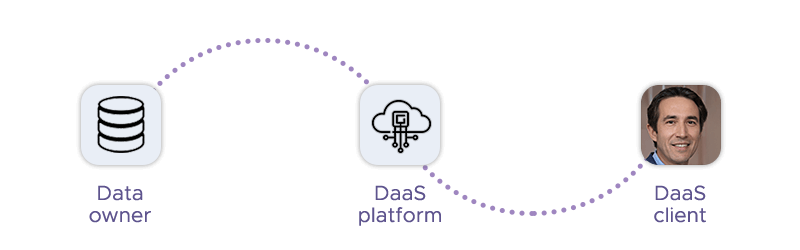
Data-as-a-Service (DaaS): Instead of building and maintaining their own scraping infrastructure, organizations can purchase ready-to-use datasets or rely on providers who deliver data on demand. This approach saves time and reduces operational complexity.
ETL (Extract, Transform, Load) pipelines: Modern data engineering tools allow businesses to collect, clean, and integrate data from multiple sources automatically. ETL pipelines ensure that data is consistent and ready for analysis.
What Is Data Transformation? A Practical Guide for Data-Driven Teams
Data transformation made simple: Explore key concepts, challenges, and how Infatica’s scraping tools help prepare data for analysis and automation.
Jovana GojkovicWhere Proxies Fit In
No matter which data extraction method a business chooses, proxies play a crucial role in making the process reliable and efficient. When organizations rely on web scraping as a modern alternative to screen scraping, they often face challenges such as:
- Rate limits that restrict the number of requests.
- Geo-blocking that prevents access to region-specific content.
- IP bans triggered by frequent or automated activity.
Proxies solve these challenges by acting as intermediaries between the scraper and the target website. By rotating IP addresses, they allow businesses to collect data at scale without interruptions, access geo-restricted or localized content, and stay anonymous and reduce the risk of blocking.
At Infatica, we provide:
- Residential proxies and datacenter proxies for stability and global coverage.
- Web scraping services that simplify large-scale data collection.
- Custom scraping-as-a-service for businesses with unique or complex data needs.
With the right proxy infrastructure in place, companies can move beyond fragile screen scraping and embrace modern, scalable, and compliant data collection methods.
Frequently Asked Questions
Screen scraping is the automated extraction of data directly from a computer screen or application interface. Unlike web scraping, it reads visual output rather than structured data, often used for legacy systems without APIs.
Screen scraping captures visual content from a program, uses pattern recognition or OCR to interpret it, and then converts it into structured formats like spreadsheets or databases for analysis and integration.
Screen scraping is fragile, slow, and error-prone. Even minor interface changes can break it. It also carries legal risks, high maintenance costs, and limited scalability compared to modern web scraping methods.
Screen scraping reads data visually from the interface, while web scraping extracts structured data from HTML or APIs. Web scraping is faster, more accurate, and scalable, especially when combined with proxy solutions.
Proxies help avoid IP bans, overcome geo-blocking, and maintain anonymity during large-scale data collection. Using residential or datacenter proxies ensures more reliable and compliant web scraping compared to fragile screen scraping.





{kind=link}
{kind=link}