






Article content


Jovana Gojkovic
6 min read
Load balancers and reverse proxies may seem similar at first glance, but each serves distinct purposes and operates differently within a network architecture. Understanding the differences between these two technologies is essential for designing resilient systems – and especially relevant for tasks like content delivery, caching, or large-scale web scraping. In this article, we’ll break down what sets load balancers apart from reverse proxies, when to use one or both, and how proxy-based solutions like those offered by Infatica can play a supporting role in data-intensive scenarios.
What Is a Load Balancer?
A load balancer is a traffic management component designed to distribute incoming network requests across multiple backend servers. Its primary goal is to ensure no single server becomes overwhelmed, enhancing both system reliability and performance. Think of it as a digital traffic cop that keeps data flowing smoothly, even during traffic spikes or server outages. There are two main types of load balancing:
- Layer 4 (Transport Layer): Routes traffic based on IP address and TCP/UDP ports without looking into the actual content of the request.
- Layer 7 (Application Layer): Makes routing decisions based on content, such as URL path, cookies, or HTTP headers – ideal for complex web applications.
Load balancers can be hardware-based (deployed as physical appliances) or software-based (implemented via tools like HAProxy, NGINX, or cloud-native solutions such as AWS Elastic Load Balancer). Their key benefits include:
- High availability through server redundancy
- Scalability by adding/removing backend servers dynamically
- Fault tolerance with automatic rerouting on failure
- Optimized performance via smart request distribution (round-robin, least connections, etc.)
What Is a Reverse Proxy?
A reverse proxy sits between clients and backend servers, forwarding client requests to the appropriate server and returning the server’s response to the client. Unlike a traditional (forward) proxy, which hides the client from the server, a reverse proxy hides the server from the client – offering performance, security, and architectural benefits. Reverse proxies are often used to:
- Handle SSL termination, offloading encryption tasks from backend servers
- Cache static content, reducing server load and improving response times
- Implement authentication or rate limiting, adding a layer of access control
- Mask server IPs, shielding infrastructure from direct exposure
Popular tools like NGINX, Apache, and HAProxy can all function as reverse proxies, and cloud-based services like Cloudflare and AWS CloudFront incorporate reverse proxy features at scale.
Forward Proxy vs Reverse Proxy: The Difference | Infatica
The reverse proxy and the forward proxy play important roles in web scraping, performance testing, online security, and more. Read this guide to learn about these proxy types!
 Vlad Khrinenko
Vlad Khrinenko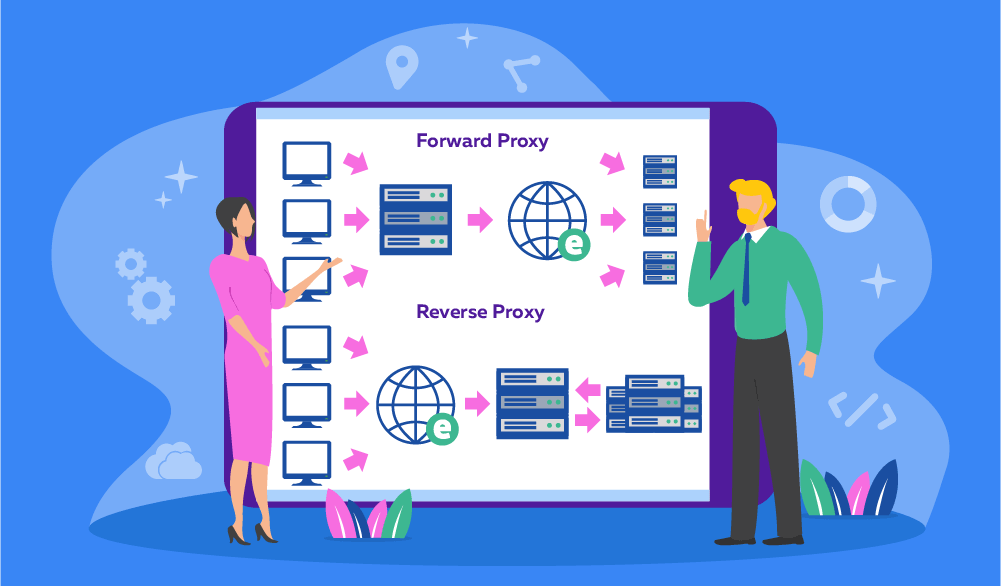
For example, when multiple microservices power a web application, a reverse proxy can route requests to the correct service based on URL patterns. It centralizes control and improves efficiency – making it a go-to solution for modern web architectures.
In scenarios such as web scraping, a reverse proxy can also help manage headers, rotate user agents, or serve as a gateway that distributes requests to multiple proxies. This is where reverse proxy principles intersect with solutions like those provided by Infatica, which help users gather data at scale without getting blocked.
Forward Proxy vs Reverse Proxy: The Difference | Infatica
The reverse proxy and the forward proxy play important roles in web scraping, performance testing, online security, and more. Read this guide to learn about these proxy types!
Vlad KhrinenkoKey Differences Between Load Balancers and Reverse Proxies
| Feature | Load Balancer | Reverse Proxy |
|---|---|---|
| Primary Purpose | Distribute traffic across multiple servers | Intercept and manage requests to backend servers |
| Traffic Source | Receives requests from clients | Also receives requests from clients |
| Routing Criteria | IP address, port, server health, connection load | URL path, headers, cookies, user agents |
| Layer of Operation | Layer 4 (Transport) and/or Layer 7 (Application) | Mostly Layer 7 (Application) |
| Caching & Compression | Rarely used | Commonly used to boost performance |
| SSL Termination | Optional, often offloaded to reverse proxy | Frequently handles SSL termination |
| Security Role | Ensures availability and balance | Provides access control, IP masking, and WAF integration |
| Visibility to Client | Typically transparent (client doesn't know it exists) | Acts as visible gateway for the client |
| Common Use Cases | Scaling web apps, failover, redundancy | Microservices routing, CDN, web scraping, access control |
| Example Tools | AWS ELB, HAProxy, NGINX (load balancing mode) | NGINX, Apache, Cloudflare, HAProxy (reverse proxy mode) |
Can a Reverse Proxy Be a Load Balancer – and Vice Versa?
Yes – and this is where the lines begin to blur. While load balancers and reverse proxies serve different primary functions, many modern tools can perform both roles depending on how they’re configured. In fact, it's not uncommon for a single piece of software – like NGINX, HAProxy, or Envoy – to act as both a load balancer and a reverse proxy simultaneously. For example:
- NGINX can accept client requests (reverse proxy role), inspect request paths, and distribute them to multiple backend servers (load balancer role).
- HAProxy can operate at both Layer 4 and Layer 7, dynamically routing traffic while also handling security and SSL termination.
When Do the Roles Overlap?
In practical terms, the distinction often comes down to intent:
- If you're focused on distributing load, you’re using load balancing.
- If you’re concerned with managing how requests reach backend services, you’re using reverse proxying.
In real-world deployments – especially in microservices, Kubernetes, or edge computing environments – combining both functions in one component can simplify infrastructure and reduce latency.
Use Cases – When to Use Each
Understanding when to use a load balancer, a reverse proxy, or both depends on your goals, whether it’s performance, resilience, security, or control.
When to Use a Load Balancer
- High-traffic applications: Distribute requests evenly to prevent overload on a single server.
- Redundancy and failover: Maintain uptime even if one or more backend servers fail.
- Horizontal scaling: Dynamically add or remove servers to match demand.
- Cloud-native environments: Essential for containerized applications and Kubernetes clusters.
When to Use a Reverse Proxy
- Microservices architecture: Route requests to the appropriate service based on URL or headers.
- SSL termination: Offload encryption tasks from backend servers to improve performance.
- Security and access control: Add authentication, rate limiting, and WAF functionality.
- Content caching: Improve performance by serving frequently requested static content.
When to Use Both Together
- Large-scale web platforms: Use a reverse proxy in front for security and smart routing, and a load balancer behind it to manage traffic distribution.
- Web scraping and data aggregation: Combine reverse proxy logic with a distributed IP network to bypass anti-bot systems and ensure request success.
Frequently Asked Questions
Yes. Tools like NGINX and HAProxy can be configured to perform both roles, managing traffic distribution and handling request routing, SSL termination, and caching – all within a unified architecture.
A proxy hides the client from the destination server, while a reverse proxy hides backend servers from the client. They operate in opposite directions but can be used together for added control and anonymity.
It depends on your setup. For large-scale or high-availability systems, combining both enhances performance, fault tolerance, and routing flexibility. Smaller applications may benefit from one or the other, depending on their goals.
Proxies rotate IP addresses and change geolocations, helping scrapers avoid detection and access geo-restricted content. Services like Infatica offer residential and datacenter proxies ideal for high-volume, stealthy data collection.
Yes. Reverse proxies improve security by masking origin servers, enforcing rate limits, handling SSL, and integrating with web application firewalls (WAFs). They act as a frontline defense against direct attacks on backend infrastructure.





{kind=link}
{kind=link}