






Article content


Jovana Gojkovic
5 min read
Nowadays, data is key – and millions of bots crawl web pages to collect it. These web crawling bots may seem simple, but they actually use interesting techniques to gather data reliably. In this guide, we’re answering the most common questions on this topic: What is crawling? What is website scraping? Do they mean the same thing? What is site scraping? And more!
Defining webpage crawling
Web crawling is the process of automatically navigating the internet by visiting web pages and following links on those pages to other pages. A web crawler, also known as a spider or bot, is a program that automatically navigates the internet by visiting web pages and following links on those pages to other pages.
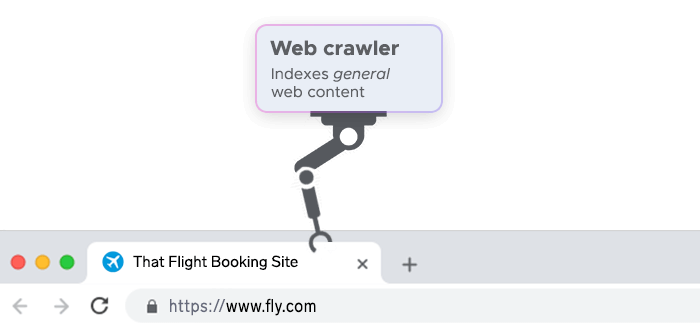
The goal of a web page crawler is typically to discover and index all the pages of a website. Site crawler can be written in any programming language and can be simple or complex depending on the task they are designed to perform.
Defining web scraping
In most cases, the terms web site crawling/scraping are used interchangeably to denote “automatic collection of data”. However, there is a technical difference between the two terms – for a more effective data collection approach, let’s explore web scraping definition.
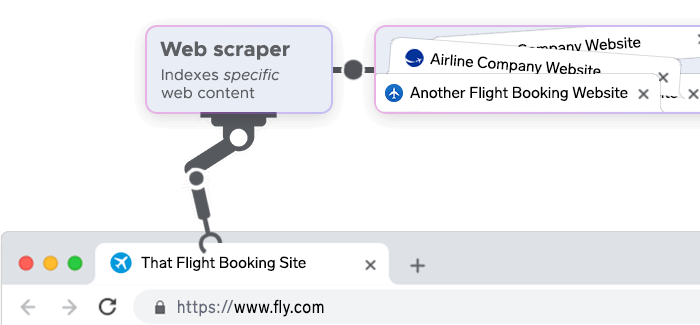
Web scraping is the process of extracting data from a website. Once the web crawler has located the pages of interest, the web scraper will then extract the relevant information. Web scraping is commonly used to gather data for analytics, market research, or to build a dataset for machine learning models.
How do these bots crawl webpages?
navigates the internet by visiting web pages and following links to other pages. It starts with a seed list of URLs to visit, then it retrieves the HTML of each page, and parses it to extract all the links on that page. The links are then added to a queue of URLs to visit next.
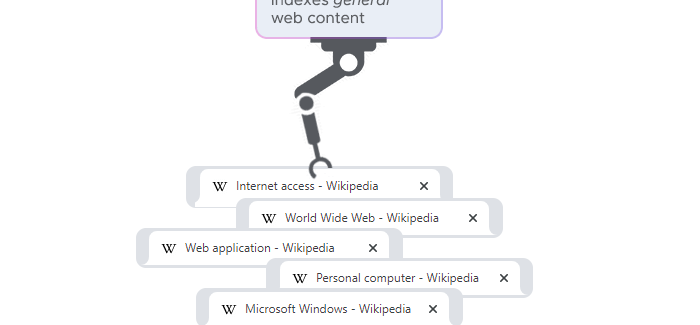
The process is repeated for each link in the queue, moving from page to page, and depth-first, until the crawler has visited all the pages it wants to, or reaches a certain depth level, or the links found no longer match the criteria set in the beginning. The information collected by the web crawler can then be used for various purposes such as indexing content via search engine crawling, monitoring websites for changes, or data mining.
What are the uses of page crawling?
Website crawling has a wide range of benefits. Web scraping uses can vary, but they are commonly used to index the content of websites for search engines, to gather information for analytics or market research, or to monitor a website for malicious activity.
- Search engine indexing: Web crawlers are used by search engines to discover and crawl websites, indexing any updated content.
- Data mining: Spiders can crawl the web to gather large amounts of data for various purposes, such as market research or sentiment analysis.
- Price comparison: Crawlers can be used to gather pricing information from different e-commerce websites for comparison.
- Content generation: Bots can crawl web pages to gather information from multiple sources to generate new content.
- Monitoring: Website crawlers can be used to monitor a website for changes or updates, such as new products or prices.
- Archiving: Web crawlers can be used to archive historical data from websites for future reference.
Which web crawling problems may you encounter?

If you want to crawl websites effectively, keep these possible roadblocks in mind:
- Scalability: Large-scale site crawlers can be computationally expensive and require a significant amount of storage.
- Dynamic content: Many websites use JavaScript or other technologies to load dynamic content, which can make it difficult for page crawlers to access all of the information on a page.
- Duplicate content: Crawling the page multiple times can lead to wasted resources and slow down the crawling process.
- Privacy and security: Website crawling can put a strain on web servers and potentially access sensitive information, which can raise privacy and security concerns.
- IP blocking: Some websites may block IP addresses of known crawlers to prevent excessive usage of their servers.
- Politeness policies: Crawling should be done in a polite manner to avoid overwhelming the target website and its servers.
- CAPTCHAs and rate limiting: Websites may implement CAPTCHAs or rate limiting to prevent automated crawling, which can make it difficult for crawlers to access the site.
- Last but not least, handling redirects, broken links and 404 errors can also be problematic.
How are proxies useful for webpage crawlers?
Proxies can help with web scraping by masking the IP address of the device or computer making the web scraping requests. This can help to avoid detection and blocking by website servers, as well as provide an additional layer of anonymity for the person or organization during the web scraping process. Additionally, using a proxy can also allow a web scraper to access a website or web page that may be blocked or restricted based on geographic location.
Infatica offers reliable, high-performance, and affordable proxies:
Conclusion
Website crawlers are an important tool for today’s web infrastructure: They help users find relevant information more easily; they allow businesses to gather information about their competitors, such as pricing and product offerings; they enable data scientists and researchers to collect large amounts of data for analysis and research purposes.
Frequently Asked Questions
The process of web scraping is used in a wide range of products and services: gathering data for search engine indexing, monitoring a website for changes or malicious activity, and identifying new sites to be added to a search engine's index, and more.
Free web crawlers can be a good option for certain use cases, such as small-scale personal projects or for testing and experimentation. However, they may not have the same capabilities or performance as paid or enterprise-level web crawlers. It also depends on the specific web crawler you are using, as some free web crawlers may be more feature-rich and reliable than others. It is important to carefully evaluate the capabilities and limitations of a free web crawler before using it for any important or critical tasks.




{kind=link}
{kind=link}